
[ad_1]
# SQL + Python Simply Is not Sufficient
For years, the components appeared easy: be taught SQL + be taught Python = get a knowledge job. Particularly as mid-sized corporations began turning into “data-driven.” Hiring managers have been completely satisfied they may get anybody who may write a half-decent GROUP BY and wrangle a pandas DataFrame with out breaking one thing. You recognize what PostgreSQL is? Get in, you bought the job! This labored for a while. Till it did not.
If you have not observed, the info skilled’s job market has undergone a structural shift. Sure, SQL and Python are nonetheless vital; they’re on each job description. However they have been demoted from differentiators to conditions.
Seemingly, you are still optimizing for the interview questions you practiced three years in the past. Overlook about it. This text is in regards to the hole between what candidates put together for and what corporations really need proper now.
# What the Job Market Is Really Asking For
A January 2026 breakdown by Future Proof Information Science of over 700 information scientist job postings discovered that Python and SQL are nonetheless among the many prime three expertise, however machine studying and AI expertise are second and fourth.
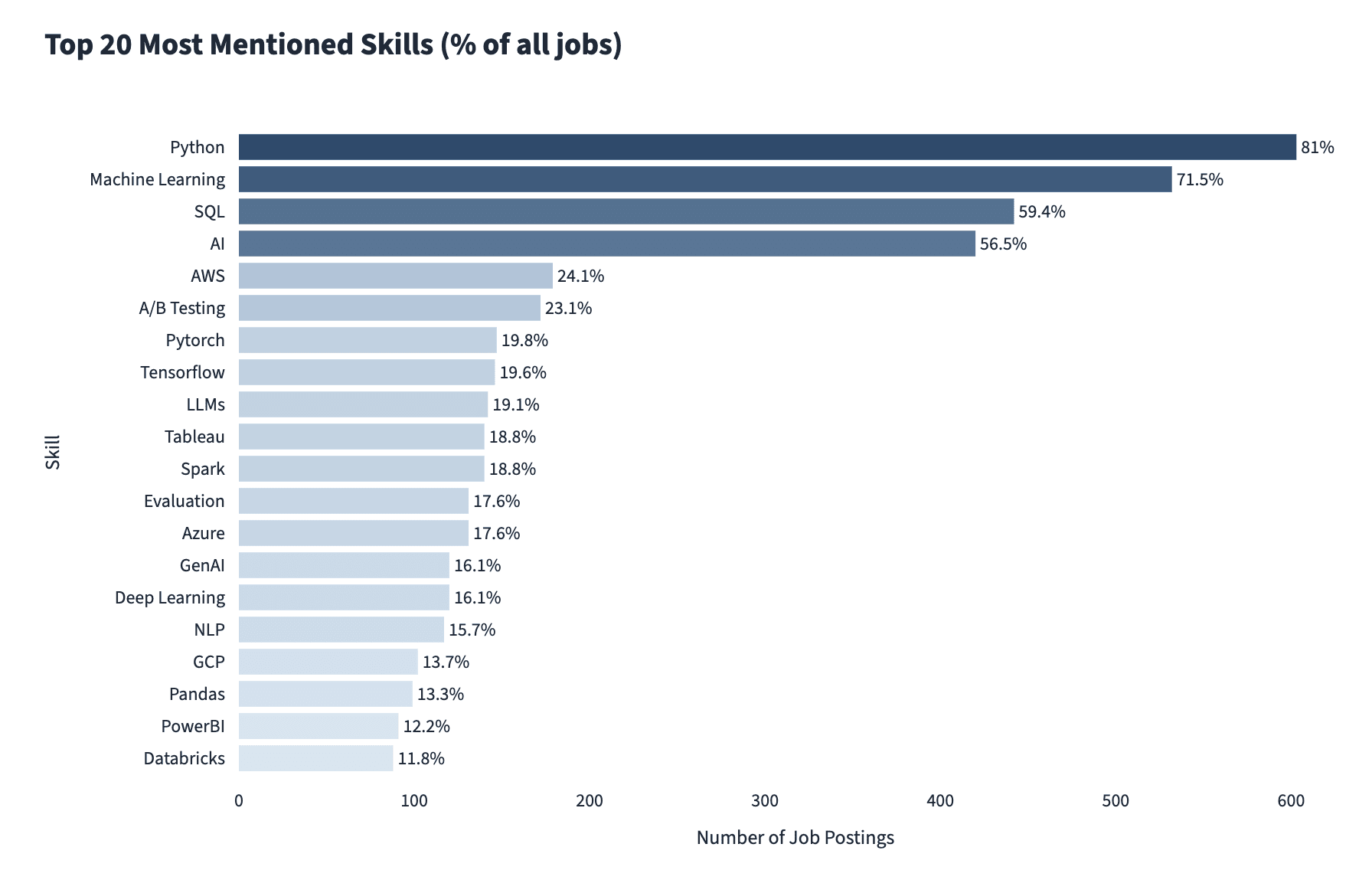
Picture Supply: Future Proof Information Science
Not all AI-related postings require hands-on AI experience, however 1 in 3 does. The most required particular AI expertise are:
- Giant language fashions (LLMs)
- Retrieval-augmented technology (RAG)
- Immediate engineering
- Vector databases
This speaks to an rising demand for information professionals who can construct and deploy AI methods.
Remember the fact that the route and the rate of this transformation matter. This jogs my memory of how machine studying went from a distinct segment requirement in 2012 to a near-universal one by 2020.
The second story is much less seen however arguably extra rapid for many candidates: the foundational engineering bar has risen sharply. Information engineering expertise — pipelines, orchestration, cloud platforms, information high quality checks — and machine studying in manufacturing — mannequin monitoring, drift detection, analysis design — at the moment are core expectations relatively than bonuses in information science job postings.
A look at any main job board confirms it: together with AI expertise, roles titled “Information Scientist” routinely listing Snowflake, dbt, Airflow, and ETL pipeline possession as necessities, not nice-to-haves.
There are 4 expertise that you’re in all probability lacking. These are the brand new differentiators within the present job market.
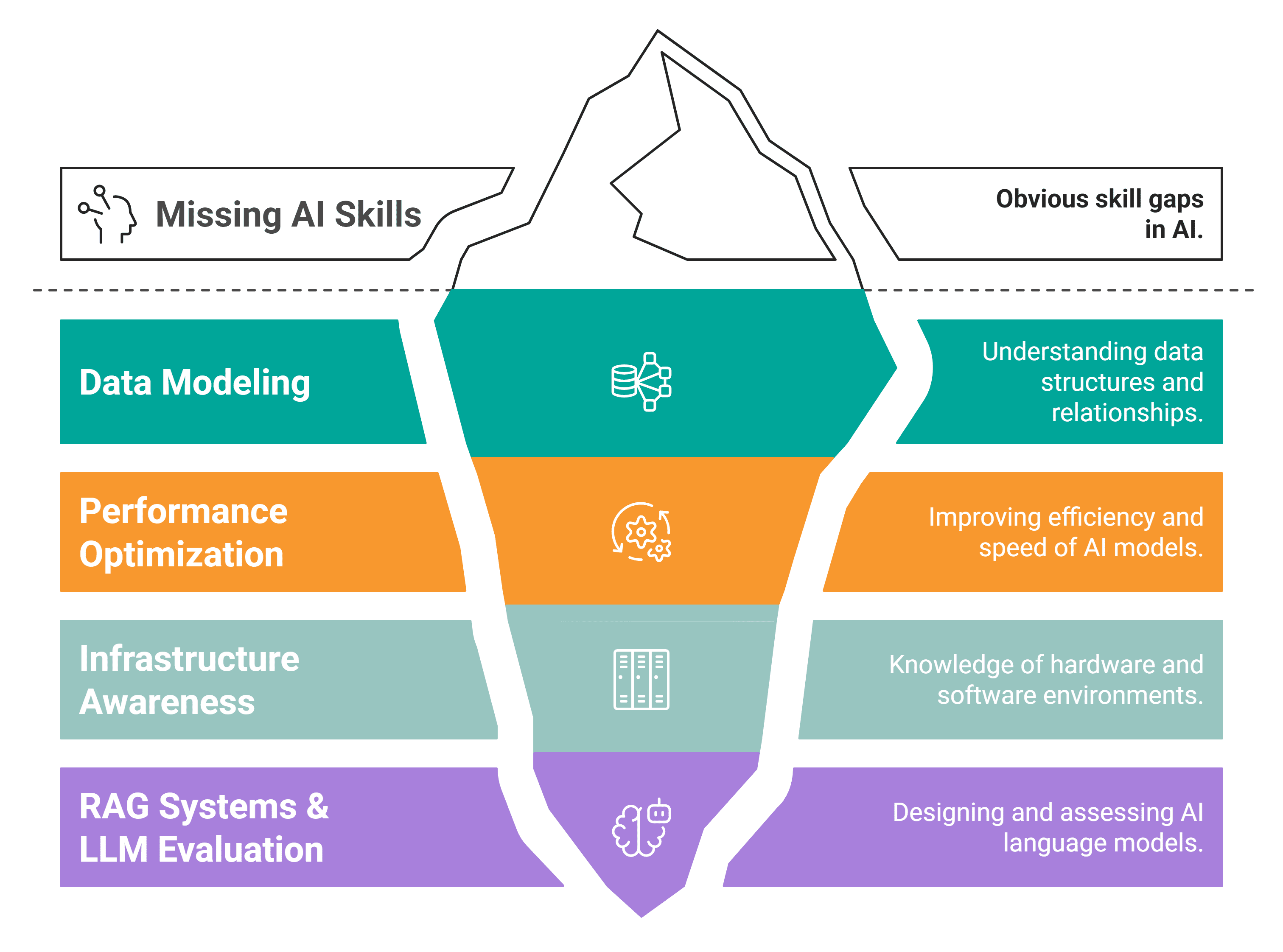
# Ability #1: Information Modeling
// What It Is
Information modeling is the flexibility to design how information must be structured, associated, and saved. Consider it as deciding what tables to create, what they characterize, and the way they relate to one another.
// Why It Turned a Differentiator
Tooling enhancements modified the panorama. Snowflake, dbt, and BigQuery all made it comparatively simple for information scientists to personal the info transformation layer. In different phrases, modeling selections that used to belong to information engineers at the moment are being handed over to information scientists.
Get a knowledge schema flawed, and also you’re in harmful waters. Usually, these errors aren’t apparent instantly. As soon as they turn out to be apparent, it is too late. Your machine studying work has already been impacted by characteristic engineering constructed on information of the flawed granularity — a direct consequence of a badly modeled basis.
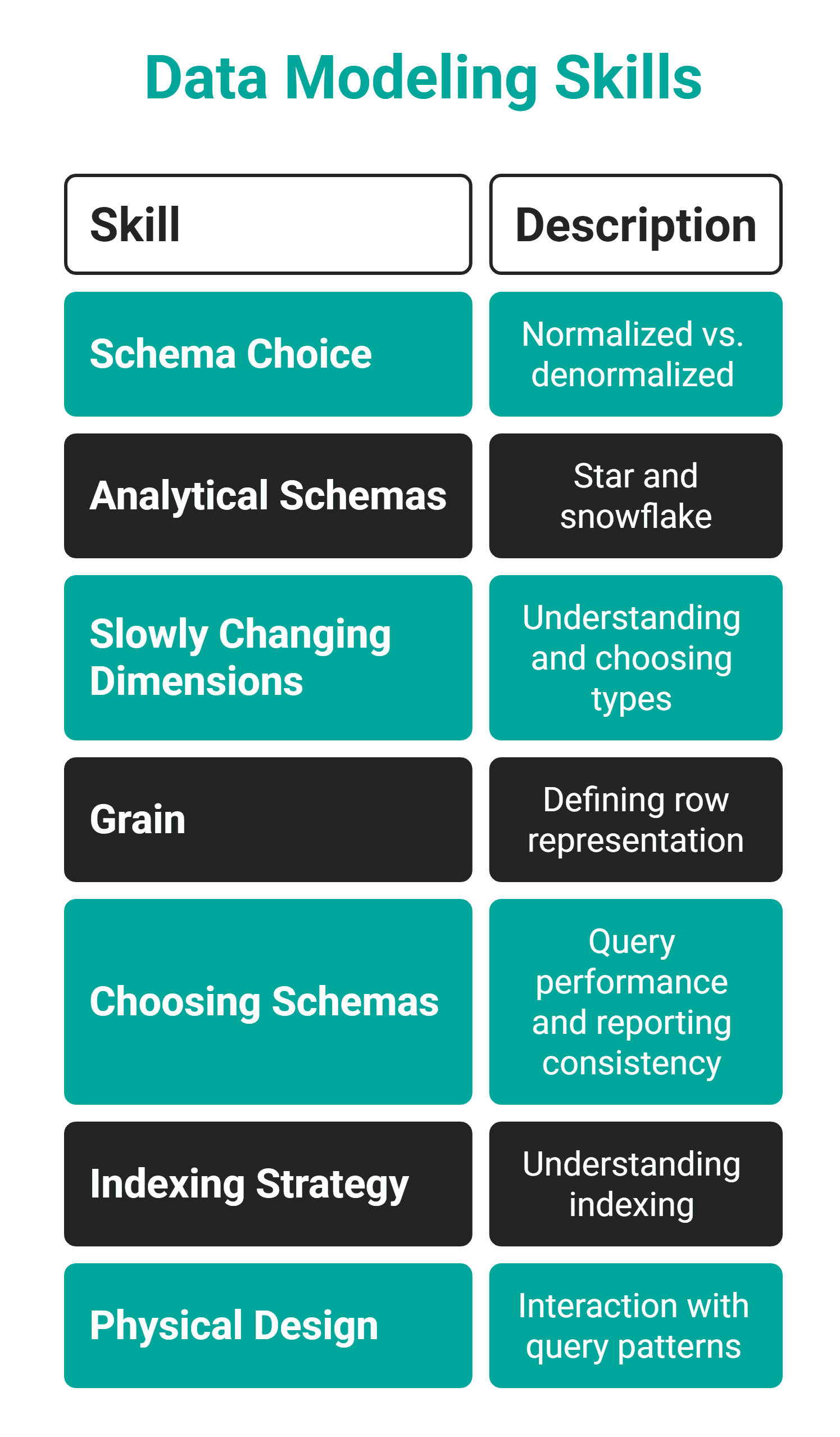
// How one can Purchase It
Take an actual dataset you’re employed with and redesign its schema from scratch. Ask your self these questions:
- What are the entities?
- What do they relate to?
- What grain is smart?
- What queries will run most incessantly?
After that, examine dimensional modeling. Kimball’s method, detailed in his ebook The Information Warehouse Toolkit, stays a helpful reference level.
# Ability #2: Efficiency Optimization
// What It Is
Efficiency optimization is knowing why a question runs the best way it does and how one can make it run quicker, cheaper, or at better scale. You possibly can optimize SQL queries, but additionally Python pipelines and information workflows usually — information scientists more and more personal them end-to-end.
// Why It Turned a Differentiator
First, information volumes have grown to the purpose the place an accurate however inefficient question can price a whole bunch of {dollars} and trip in manufacturing.
Second, as talked about earlier, information scientists now need to personal way more of the pipeline than they did earlier than. Your code must be production-ready, not simply runnable in Jupyter notebooks.
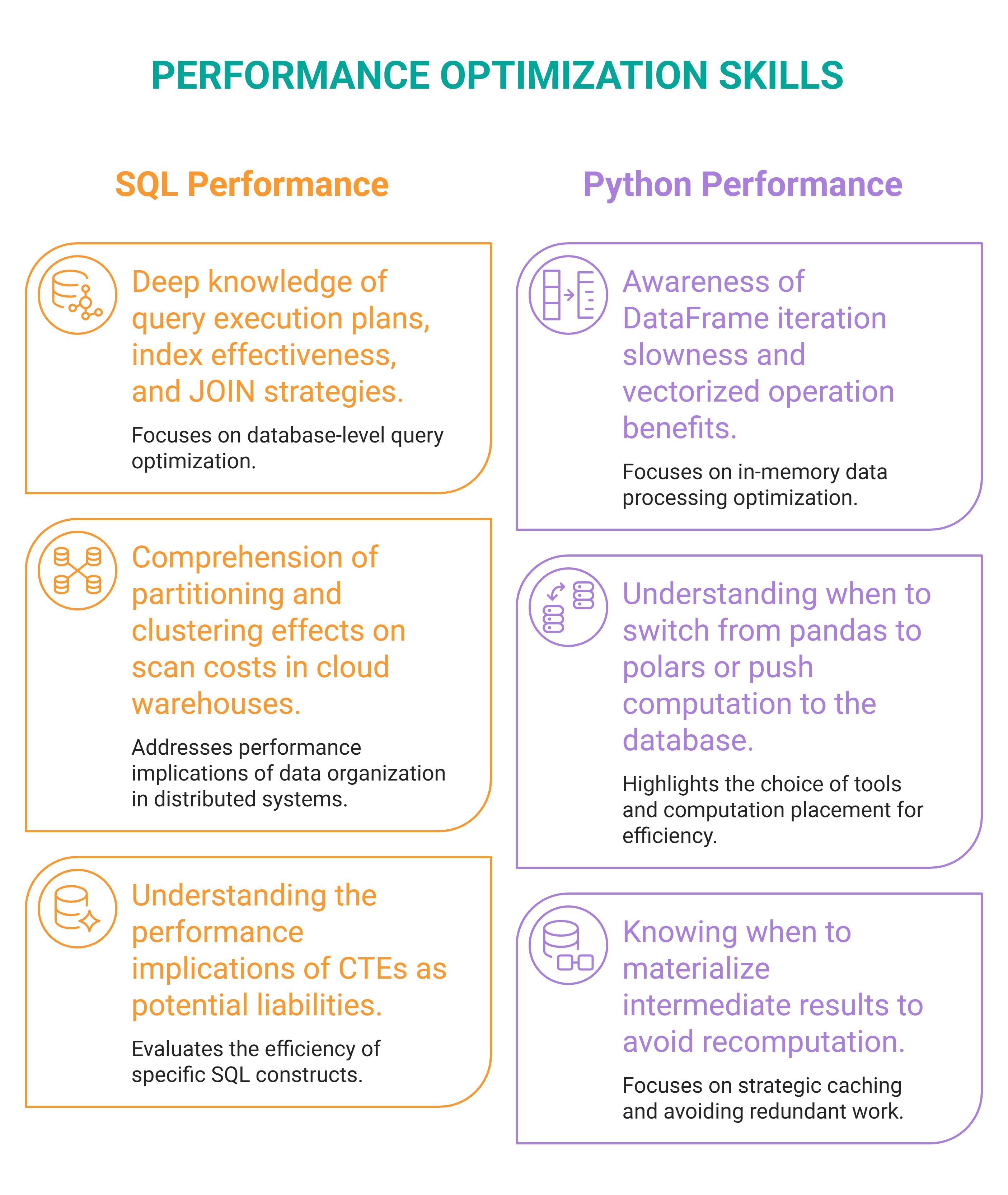
// How one can Purchase It
Decide a number of advanced SQL queries you have written, run EXPLAIN ANALYZE on them, and browse what the question planner really did. Then use that to optimize the question. You will seemingly discover at the very least one index, restructuring, or rewrite that improves every question.
For a gradual Python pipeline, profile it. There are two major instruments for time:
- cProfile: Run it with
python -m cProfile -s cumulative your_script.pyand take a look at the highest of the output to see the capabilities consuming essentially the most cumulative time. - line_profiler: Goes deeper by exhibiting execution time line by line inside a selected operate. Use it as soon as cProfile has instructed you which operate is gradual and you should know why.
For reminiscence, use memory_profiler.
Discover the bottleneck — is it gradual as a result of a Python loop must be vectorized? Is information loaded into reminiscence as a substitute of in chunks? — repair it, and measure the distinction.
# Ability #3: Infrastructure Consciousness
// What It Is
This talent means you perceive the methods information lives in and strikes by means of. These methods embody cloud platforms, distributed compute, information pipelines, storage codecs, and price fashions.
You must know sufficient in regards to the infrastructure to design methods which can be deployable into it.
// Why It Turned a Differentiator
Once more, as a result of an excellent chunk of a knowledge engineer’s job has fallen into a knowledge scientist’s lap. In case you’re depending on information engineers for each infrastructure determination, you are successfully making a bottleneck — and that is not one thing hiring managers are in search of.
Infrastructure consciousness contains these major interconnected areas.
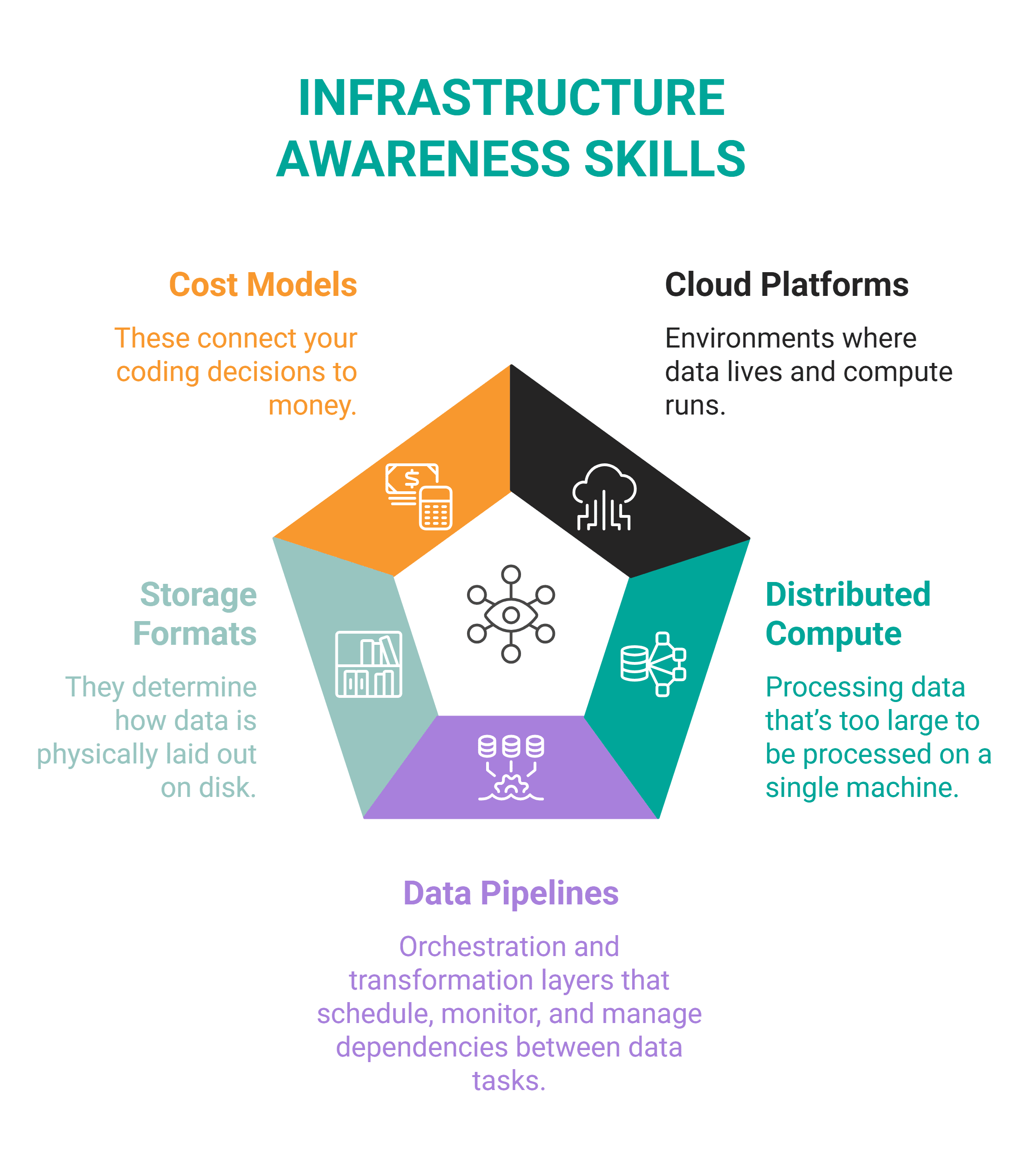
You will most probably need to familiarize your self with these instruments.
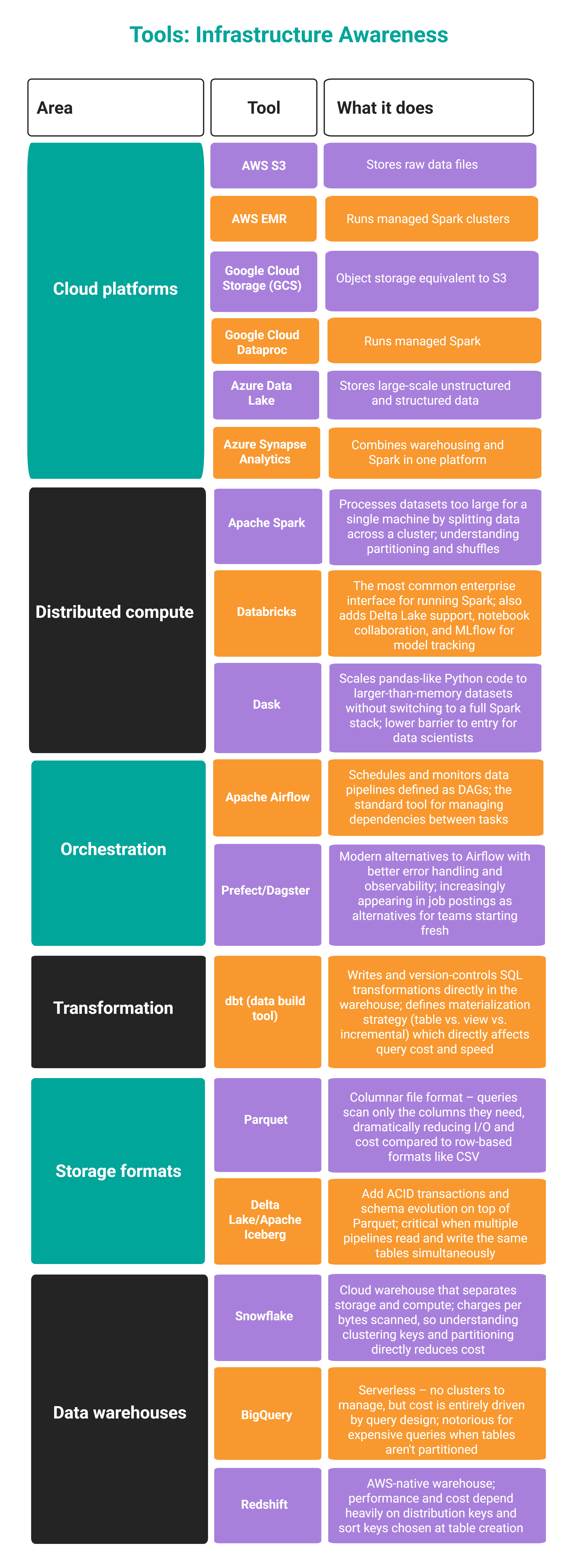
// How one can Purchase It
Organize a session together with your information engineering workforce. Sit with them and ask them to stroll you thru a pipeline end-to-end. Perceive the place information lives, the way it’s partitioned, and what occurs when one thing breaks.
Then step up by constructing a small pipeline your self: use a free cloud tier, perceive the price and execution metrics, then intentionally break the pipeline to grasp the way it fails.
# Ability #4: Designing RAG Techniques, Evaluating LLM Outputs, and Working AI Experiments
// What It Is
This cluster of expertise pertains to sensible AI work. It’s a must to know how one can design retrieval-augmented technology (RAG) methods (connecting LLMs to actual information sources), construct analysis frameworks (measuring whether or not an LLM-powered characteristic is definitely working), and run experiments on AI options.
// Why It Turned a Differentiator
AI instruments are the explanation. They made it doable to construct a RAG pipeline with out in depth analysis information. Frameworks like LangChain and LlamaIndex, mixed with cloud-native vector databases, lowered the barrier considerably.
So the query is now not whether or not it may be constructed — sure, it may be. However can or not it’s constructed effectively, evaluated, and trusted in manufacturing? Answering that query is what you will need to be capable of do: outline metrics, design experiments, and measure outcomes.
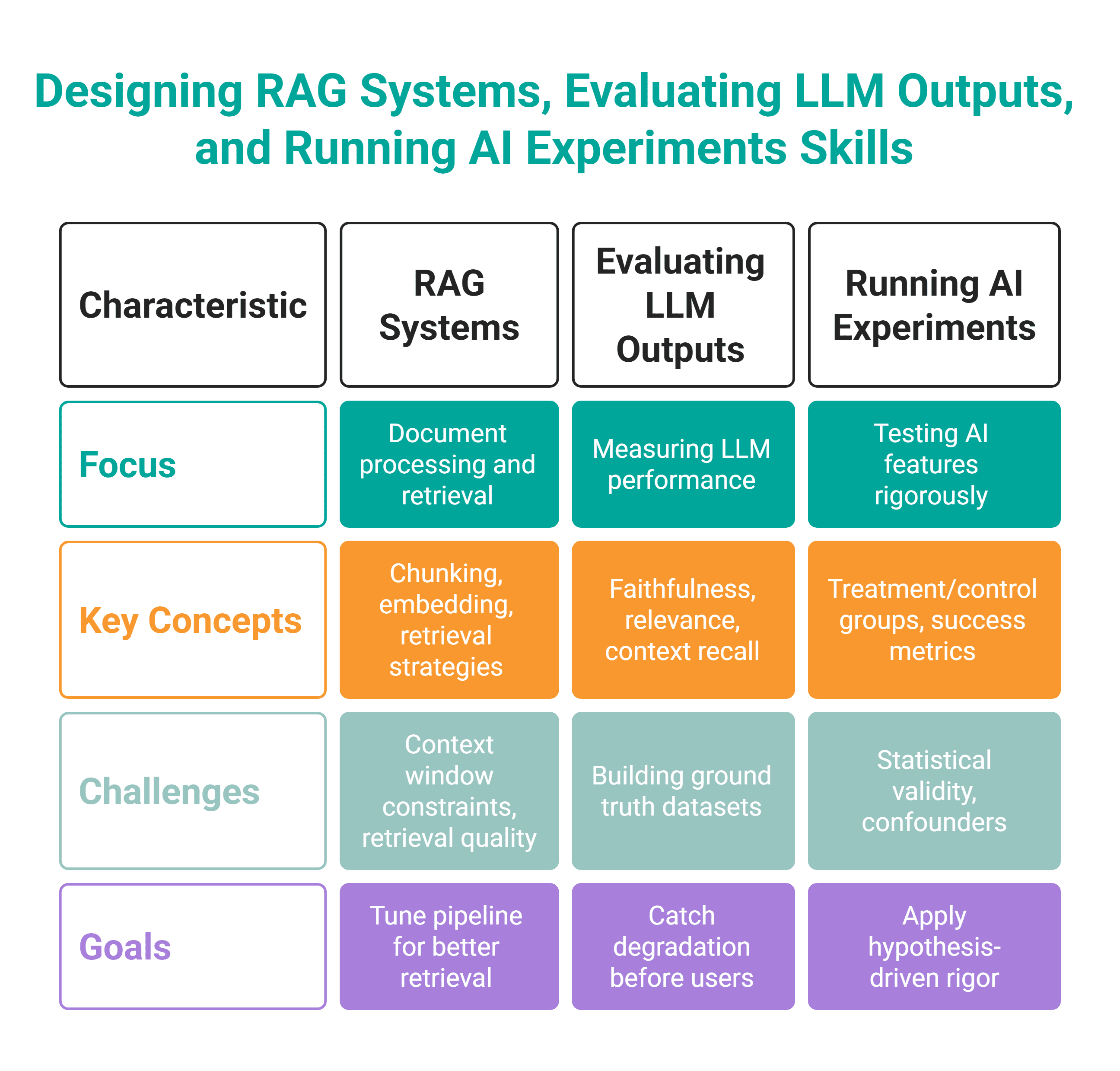
In making use of these expertise, you’ll use these instruments.

// How one can Purchase It
Discover some interview questions that can assist you refine your AI considering. Listed below are some examples from AI Product & GenAI interview questions on StrataScratch.
Instance #1: Measuring AI Function Rollout in Retail Shops
How would you measure the impression of an AI-powered stock advice system being rolled out to a pattern of retail shops? How would you design the experiment and account for store-level variation?
Instance #2: RAG System Structure
Describe how you’ll architect a RAG system from scratch. What elements are wanted, and the way would you optimize retrieval high quality?
After you have made your considering clear, construct a small RAG software: select a website, embed a doc corpus, wire up retrieval, and consider the outputs utilizing a structured metric.
Additionally, design an experiment: write out a speculation, outline the metrics, and assume by means of a sound take a look at to guage it.
# Conclusion
The 4 expertise — information modeling, efficiency optimization, infrastructure consciousness, and sensible AI expertise — are what comprise the hole between you and the job market. Hopefully you will not fall into it. To make sure you do not, this text has included sensible recommendation on how one can purchase every one.
Nate Rosidi is a knowledge scientist and in product technique. He is additionally an adjunct professor educating analytics, and is the founding father of StrataScratch, a platform serving to information scientists put together for his or her interviews with actual interview questions from prime corporations. Nate writes on the newest tendencies within the profession market, offers interview recommendation, shares information science tasks, and covers every part SQL.
[ad_2]


")

{kind=link}