
Picture by Creator
# Introduction
Bear in mind when constructing a full-stack software required costly cloud credit, pricey API keys, and a workforce of engineers? These days are formally over. By 2026, builders can construct, deploy, and scale a production-ready software utilizing nothing however free instruments, together with the massive language fashions (LLMs) that energy its intelligence.
The panorama has shifted dramatically. Open-source fashions now problem their industrial counterparts. Free AI coding assistants have grown from easy autocomplete instruments to full coding brokers that may architect total options. And maybe most significantly, you may run state-of-the-art fashions domestically or via beneficiant free tiers with out spending a dime.
On this complete article, we’ll construct a real-world software — an AI assembly notes summarizer. Customers will add voice recordings, and our app will transcribe them, extract key factors and motion gadgets, and show the whole lot in a clear dashboard, all utilizing utterly free instruments.
Whether or not you’re a pupil, a bootcamp graduate, or an skilled developer seeking to prototype an concept, this tutorial will present you the way to leverage one of the best free AI instruments out there. Start by understanding why free LLMs work so nicely right now.
# Understanding Why Free Giant Language Fashions Work Now
Simply two years in the past, constructing an AI-powered app meant budgeting for OpenAI API credit or renting costly GPU situations. The economics have essentially shifted.
The hole between industrial and open-source LLMs has practically disappeared. Fashions like GLM-4.7-Flash from Zhipu AI display that open-source can obtain state-of-the-art efficiency whereas being utterly free to make use of. Equally, LFM2-2.6B-Transcript was particularly designed for assembly summarization and runs solely on-device with cloud-level high quality.
What this implies for you is that you’re now not locked right into a single vendor. If one mannequin doesn’t work in your use case, you may swap to a different with out altering your infrastructure.
// Becoming a member of the Self-Hosted Motion
There’s a rising desire for native AI operating fashions by yourself {hardware} fairly than sending knowledge to the cloud. This is not nearly price; it’s about privateness, latency, and management. With instruments like Ollama and LM Studio, you may run highly effective fashions on a laptop computer.
// Adopting the “Convey Your Personal Key” Mannequin
A brand new class of instruments has emerged: open-source purposes which can be free however require you to offer your personal API keys. This provides you final flexibility. You need to use Google’s Gemini API (which gives lots of of free requests each day) or run solely native fashions with zero ongoing prices.
# Selecting Your Free Synthetic Intelligence Stack
Breaking down one of the best free choices for every element of our software entails choosing instruments that steadiness efficiency with ease of use.
// Transcription Layers: Speech-to-Textual content
For changing audio to textual content, we’ve glorious free speech-to-text (STT) instruments.
| Instrument | Sort | Free Tier | Greatest For |
|---|---|---|---|
| OpenAI Whisper | Open-source mannequin | Limitless (self-hosted) | Accuracy, a number of languages |
| Whisper.cpp | Privateness-focused implementation | Limitless (open-source) | Privateness-sensitive eventualities |
| Gemini API | Cloud API | 60 requests/minute | Fast prototyping |
For our mission, we’ll use Whisper, which you’ll run domestically or via free hosted choices. It helps over 100 languages and produces high-quality transcripts.
// Summarization and Evaluation: The Giant Language Mannequin
That is the place you’ve probably the most selections. All choices under are utterly free:
| Mannequin | Supplier | Sort | Specialization |
|---|---|---|---|
| GLM-4.7-Flash | Zhipu AI | Cloud (free API) | Basic goal, coding |
| LFM2-2.6B-Transcript | Liquid AI | Native/on-device | Assembly summarization |
| Gemini 1.5 Flash | Cloud API | Lengthy context, free tier | |
| GPT-OSS Swallow | Tokyo Tech | Native/self-hosted | Japanese/English reasoning |
For our assembly summarizer, the LFM2-2.6B-Transcript mannequin is especially attention-grabbing; it was actually educated for this actual use case and runs in beneath 3GB of RAM.
// Accelerating Improvement: Synthetic Intelligence Coding Assistants
Earlier than we write a single line of code, take into account the instruments that assist us construct extra effectively throughout the built-in growth surroundings (IDE):
| Instrument | Free Tier | Sort | Key Characteristic |
|---|---|---|---|
| Comate | Full free | VS Code extension | SPEC-driven, multi-agent |
| Codeium | Limitless free | IDE extension | 70+ languages, quick inference |
| Cline | Free (BYOK) | VS Code extension | Autonomous file modifying |
| Proceed | Full open-source | IDE extension | Works with any LLM |
| bolt.diy | Self-hosted | Browser IDE | Full-stack technology |
Our advice: For this mission, we’ll use Codeium for its limitless free tier and velocity, and we’ll preserve Proceed as a backup for when we have to swap between totally different LLM suppliers.
// Reviewing the Conventional Free Stack
- Frontend: React (free and open-source)
- Backend: FastAPI (Python, free)
- Database: SQLite (file-based, no server wanted)
- Deployment: Vercel (beneficiant free tier) + Render (for backend)
# Reviewing the Mission Plan
Defining the applying workflow:
- Consumer uploads an audio file (assembly recording, voice memo, lecture)
- The backend receives the file and passes it to Whisper for transcription
- The transcribed textual content is distributed to an LLM for summarization
- The LLM extracts key dialogue factors, motion gadgets, and selections
- Outcomes are saved in SQLite
- The person sees a clear dashboard with transcript, abstract, and motion gadgets
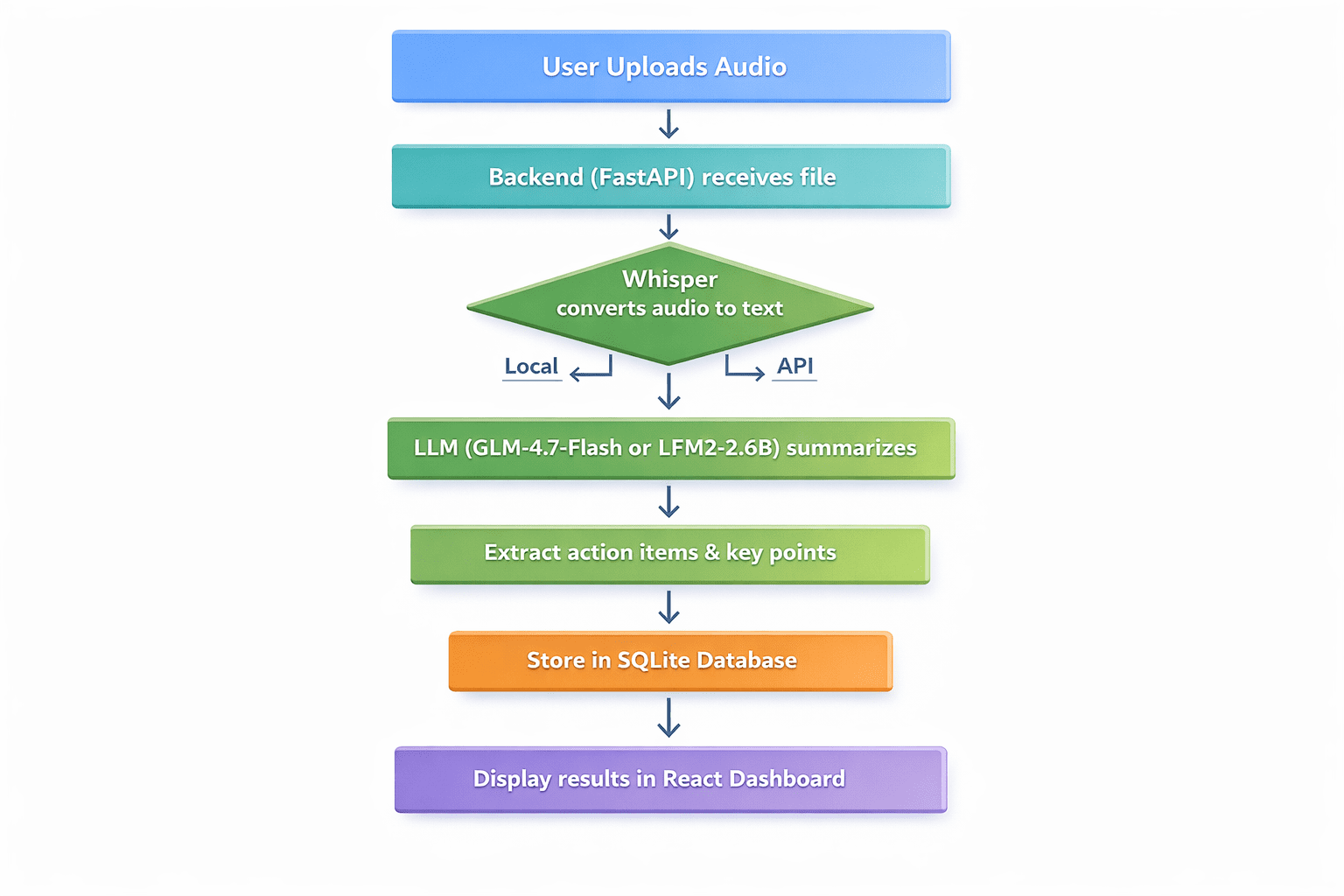
Skilled flowchart diagram with seven sequential steps | Picture by Creator
// Stipulations
- Python 3.9+ put in
- Node.js and npm put in
- Fundamental familiarity with Python and React
- A code editor (VS Code beneficial)
// Step 1: Setting Up the Backend with FastAPI
First, create our mission listing and arrange a digital surroundings:
mkdir meeting-summarizer
cd meeting-summarizer
python -m venv venv
Activate the digital surroundings:
# On Home windows
venvScriptsactivate
# On Linux/macOS
supply venv/bin/activate
Set up the required packages:
pip set up fastapi uvicorn python-multipart openai-whisper transformers torch openai
Now, create the principal.py file for our FastAPI software and add this code:
from fastapi import FastAPI, File, UploadFile, HTTPException
from fastapi.middleware.cors import CORSMiddleware
import whisper
import sqlite3
import json
import os
from datetime import datetime
app = FastAPI()
# Allow CORS for React frontend
app.add_middleware(
CORSMiddleware,
allow_origins=["http://localhost:3000"],
allow_methods=["*"],
allow_headers=["*"],
)
# Initialize Whisper mannequin - utilizing "tiny" for quicker CPU processing
print("Loading Whisper mannequin (tiny)...")
mannequin = whisper.load_model("tiny")
print("Whisper mannequin loaded!")
# Database setup
def init_db():
conn = sqlite3.join('conferences.db')
c = conn.cursor()
c.execute('''CREATE TABLE IF NOT EXISTS conferences
(id INTEGER PRIMARY KEY AUTOINCREMENT,
filename TEXT,
transcript TEXT,
abstract TEXT,
action_items TEXT,
created_at TIMESTAMP)''')
conn.commit()
conn.shut()
init_db()
async def summarize_with_llm(transcript: str) -> dict:
"""Placeholder for LLM summarization logic"""
# This will likely be applied in Step 2
return {"abstract": "Abstract pending...", "action_items": []}
@app.publish("/add")
async def upload_audio(file: UploadFile = File(...)):
file_path = f"temp_{file.filename}"
with open(file_path, "wb") as buffer:
content material = await file.learn()
buffer.write(content material)
attempt:
# Step 1: Transcribe with Whisper
outcome = mannequin.transcribe(file_path, fp16=False)
transcript = outcome["text"]
# Step 2: Summarize (To be crammed in Step 2)
summary_result = await summarize_with_llm(transcript)
# Step 3: Save to database
conn = sqlite3.join('conferences.db')
c = conn.cursor()
c.execute(
"INSERT INTO conferences (filename, transcript, abstract, action_items, created_at) VALUES (?, ?, ?, ?, ?)",
(file.filename, transcript, summary_result["summary"],
json.dumps(summary_result["action_items"]), datetime.now())
)
conn.commit()
meeting_id = c.lastrowid
conn.shut()
os.take away(file_path)
return {
"id": meeting_id,
"transcript": transcript,
"abstract": summary_result["summary"],
"action_items": summary_result["action_items"]
}
besides Exception as e:
if os.path.exists(file_path):
os.take away(file_path)
elevate HTTPException(status_code=500, element=str(e))
// Step 2: Integrating the Free Giant Language Mannequin
Now, let’s implement the summarize_with_llm() operate. We’ll present two approaches:
Possibility A: Utilizing GLM-4.7-Flash API (Cloud, Free)
from openai import OpenAI
async def summarize_with_llm(transcript: str) -> dict:
consumer = OpenAI(api_key="YOUR_FREE_ZHIPU_KEY", base_url="https://open.bigmodel.cn/api/paas/v4/")
response = consumer.chat.completions.create(
mannequin="glm-4-flash",
messages=[
{"role": "system", "content": "Summarize the following meeting transcript and extract action items in JSON format."},
{"role": "user", "content": transcript}
],
response_format={"sort": "json_object"}
)
return json.masses(response.selections[0].message.content material)
Possibility B: Utilizing Native LFM2-2.6B-Transcript (Native, Fully Free)
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
async def summarize_with_llm_local(transcript):
model_name = "LiquidAI/LFM2-2.6B-Transcript"
tokenizer = AutoTokenizer.from_pretrained(model_name)
mannequin = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto"
)
immediate = f"Analyze this transcript and supply a abstract and motion gadgets:nn{transcript}"
inputs = tokenizer(immediate, return_tensors="pt").to(mannequin.system)
with torch.no_grad():
outputs = mannequin.generate(**inputs, max_new_tokens=500)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
// Step 3: Creating the React Frontend
Construct a easy React frontend to work together with our API. In a brand new terminal, create a React app:
npx create-react-app frontend
cd frontend
npm set up axios
Substitute the contents of src/App.js with:
import React, { useState } from 'react';
import axios from 'axios';
import './App.css';
operate App() {
const [file, setFile] = useState(null);
const [uploading, setUploading] = useState(false);
const [result, setResult] = useState(null);
const [error, setError] = useState('');
const handleUpload = async () => {
if (!file) { setError('Please choose a file'); return; }
setUploading(true);
const formData = new FormData();
formData.append('file', file);
attempt {
const response = await axios.publish('http://localhost:8000/add', formData);
setResult(response.knowledge);
} catch (err) err.message));
lastly { setUploading(false); }
};
return (
{outcome && (
Abstract
{outcome.abstract}
Motion Gadgets
{outcome.action_items.map((it, i) => - {it}
)}
)}
);
}
export default App;
// Step 4: Operating the Utility
- Begin the backend: In the primary listing together with your digital surroundings lively, run
uvicorn principal:app --reload - Begin the frontend: In a brand new terminal, within the frontend listing, run
npm begin - Open http://localhost:3000 in your browser and add a check audio file
Dashboard interface displaying abstract outcomes | Picture by Creator
# Deploying the Utility for Free
As soon as your app works domestically, it’s time to deploy it to the world — nonetheless free of charge. Render gives a beneficiant free tier for net providers. Push your code to a GitHub repository, create a brand new Net Service on Render, and use these settings:
- Setting: Python 3
- Construct Command:
pip set up -r necessities.txt - Begin Command:
uvicorn principal:app --host 0.0.0.0 --port $PORT
Create a necessities.txt file:
fastapi
uvicorn
python-multipart
openai-whisper
transformers
torch
openai
Notice: Whisper and Transformers require vital disk house. In the event you hit free tier limits, think about using a cloud API for transcription as a substitute.
// Deploying the Frontend on Vercel
Vercel is the simplest approach to deploy React apps:
- Set up Vercel CLI:
npm i -g vercel - In your frontend listing, run
vercel - Replace your API URL in
App.jsto level to your Render backend
// Exploring Native Deployment Options
If you wish to keep away from cloud internet hosting solely, you may deploy each frontend and backend on a neighborhood server utilizing instruments like ngrok to show your native server quickly.
# Conclusion
We have simply constructed a production-ready AI software utilizing nothing however free instruments. Let’s recap what we achieved:
- Transcription: Used OpenAI’s Whisper (free, open-source)
- Summarization: Leveraged GLM-4.7-Flash or LFM2-2.6B (each utterly free)
- Backend: Constructed with FastAPI (free)
- Frontend: Created with React (free)
- Database: Used SQLite (free)
- Deployment: Deployed on Vercel and Render (free tiers)
- Improvement: Accelerated with free AI coding assistants like Codeium
The panorama free of charge AI growth has by no means been extra promising. Open-source fashions now compete with industrial choices. Native AI instruments give us privateness and management. And beneficiant free tiers from suppliers like Google and Zhipu AI allow us to prototype with out monetary danger.
Shittu Olumide is a software program engineer and technical author enthusiastic about leveraging cutting-edge applied sciences to craft compelling narratives, with a eager eye for element and a knack for simplifying advanced ideas. It’s also possible to discover Shittu on Twitter.

{kind=link}