
TL;DR: This information supplies a transparent framework for navigating the fragmented marketplace for knowledge extraction software program. It clarifies the three foremost classes of instruments primarily based in your knowledge supply: ETL/ELT platforms for shifting structured knowledge between functions and databases, internet scrapers for extracting public data from web sites, and Clever Doc Processing (IDP) for extracting knowledge from unstructured enterprise paperwork, akin to invoices and contracts. For many operational challenges, the perfect answer is an end-to-end IDP workflow that integrates ingestion, AI-powered seize, automated validation, and seamless ERP integration. The ROI of this strategy is strategic, serving to to stop monetary worth leakage and straight contributing to measurable features, a $40,000 enhance in Internet Working Revenue.
You’ve probably heard the outdated laptop science saying: “Rubbish In, Rubbish Out.” It’s the quiet motive so many costly AI initiatives are failing to ship. The issue is not at all times the AI; it is the standard of the information we’re feeding it. A 2024 business report discovered {that a} startling 77% of corporations admit their knowledge is common, poor, or very poor when it comes to AI readiness. The wrongdoer is the chaotic, unstructured data that flows into enterprise operations each day by way of paperwork like invoices, contracts, and buy orders.
Your seek for a knowledge extraction answer could have been complicated. You’d have come throughout developer-focused database instruments, easy internet scrapers, and superior doc processing platforms, all underneath the identical umbrella. The query is, what do you have to spend money on? In the end, that you must make sense of messy, unstructured paperwork. The important thing to that is not discovering a greater device; it is asking the suitable query about your knowledge supply.
This information supplies a transparent framework to diagnose your particular knowledge problem and presents a sensible playbook for fixing it. We are going to present you learn how to overcome the restrictions of conventional OCR and guide entry, constructing an AI-ready basis. The result’s a workflow that may scale back doc processing prices by as a lot as 80% and obtain over 98% knowledge accuracy, enabling the seamless move of data trapped in your paperwork.
The info extraction spectrum: A framework for readability
The seek for knowledge extraction software program might be complicated as a result of the time period is usually used to explain three utterly completely different sorts of instruments that remedy three completely different issues. The suitable answer relies upon completely on the place your knowledge lives. Understanding the spectrum is step one to discovering a device that truly works for your online business.
1. Public internet knowledge (Internet Scraping)
- What it’s: This class contains instruments designed to tug publicly accessible data from web sites robotically. Widespread use circumstances embrace gathering competitor pricing, gathering product critiques, or aggregating actual property listings.
- Who it is for: Advertising groups, e-commerce analysts, and knowledge scientists.
- Backside line: Select this class in case your knowledge is structured on public web sites.
- Main options: This house is occupied by platforms like Shiny Information and Apify, which provide sturdy proxy networks and pre-built scrapers for large-scale public knowledge assortment. No-code instruments like Octoparse are additionally common for non-technical customers.
2. Structured software and database knowledge (ETL/ELT)
- What it’s: This software program strikes already structured knowledge from one system to a different. The method is often known as Extract, Rework, Load (ETL). A typical use case includes syncing gross sales knowledge from a CRM, akin to Salesforce, right into a central knowledge warehouse for enterprise intelligence reporting.
- Who it is for: Information engineers and IT departments.
- Backside line: Select this class in case your knowledge is already organized inside a database or a SaaS software.
- Main options: The market leaders listed below are platforms like Fivetran and Airbyte. They specialise in offering lots of of pre-built connectors to SaaS functions and databases, automating a course of that may in any other case require important {custom} engineering.
3. Unstructured doc knowledge (Clever Doc Processing – IDP)
- What it’s: That is AI-powered software program constructed to learn and perceive the unstructured or semi-structured paperwork that run your online business: the PDFs, emails, scans, invoices, buy orders, and contracts. It finds the precise data you want—like an bill quantity or contract renewal date—and turns it into clear, structured knowledge.
- Who it is for: Finance, Operations, Procurement, Authorized, and Healthcare groups.
- Backside line: Select this class in case your knowledge is trapped inside paperwork. That is the most typical and expensive problem for enterprise operations.
- Main options: This class comprises specialised doc knowledge extraction software program like Nanonets, Rossum, ABBYY, and Tungsten Automation (previously Kofax). Developer-focused providers like Amazon Textract additionally match right here. In contrast to internet scrapers, these platforms are engineered with superior AI to deal with document-specific challenges like format variations, desk extraction, and handwriting recognition.
The 2024 business report we cited earlier additionally confirms it is probably the most important bottleneck, with over 62% of procurement processes and 59% of authorized contract administration nonetheless being extremely guide as a consequence of doc complexity. The remainder of this information will deal with this subject.
The strategic operator’s playbook for doc knowledge extraction
Doc knowledge extraction has developed from a easy effectivity device right into a strategic crucial for enterprise AI adoption. As companies look to 2026’s strongest AI functions, significantly these using Retrieval-Augmented Technology (RAG), the standard of their inner knowledge turns into more and more essential. However, even superior AI fashions like Gemini, Claude, or ChatGPT wrestle with imperfect doc scans, and accuracy charges for these main LLMs hover round 60-70% for doc processing duties.
This actuality underscores that profitable AI implementation requires extra than simply highly effective fashions – it calls for a complete platform with human oversight to make sure dependable knowledge extraction and validation.
A contemporary IDP answer will not be a single device however an end-to-end workflow engineered to show doc chaos right into a structured, dependable, and safe asset. This playbook outlines the 4 crucial levels of the workflow and supplies a sensible two-week implementation plan.
Earlier than we proceed, the desk beneath supplies a fast overview of the most typical and high-impact knowledge extraction functions throughout numerous departments. It showcases the precise paperwork, the kind of knowledge extracted, and the strategic enterprise outcomes achieved.
| Business | Widespread Paperwork | Key Information Extracted | Strategic Enterprise Final result |
|---|---|---|---|
| Finance & Accounts Payable | Invoices, Receipts, Financial institution Statements, Expense Experiences | Vendor Identify, Bill Quantity, Line Objects, Whole Quantity, Transaction Particulars | Speed up the monetary shut by automating bill coding and 3-way matching; optimize working capital by making certain on-time funds and stopping errors. |
| Procurement & Provide Chain | Buy Orders, Contracts, Payments of Lading, Customs Kinds | PO Quantity, Provider Particulars, Contract Renewal Date, Cargo ID, HS Codes | Mitigate worth leakage by robotically flagging off-contract spend and unfulfilled provider obligations; shift procurement from transactional work to strategic provider administration. |
| Healthcare & Insurance coverage | HCFA-1500/CMS-1500 Declare Kinds, Digital Well being Information (EHRs), Affected person Onboarding Kinds | Affected person ID, Process Codes (CPT), Analysis Codes (ICD), Supplier NPI, Scientific Notes | Speed up claims-to-payment cycles and scale back denials; create high-quality, structured datasets from unstructured EHRs to energy predictive fashions and enhance scientific choice help. |
| Authorized | Service Agreements, Non-Disclosure Agreements (NDAs), Grasp Service Agreements (MSAs) | Efficient Date, Termination Clause, Legal responsibility Limits, Governing Legislation | Cut back contract overview cycles and operational danger by robotically extracting key clauses, dates, and obligations; uncover hidden worth leakage by auditing contracts for non-compliance at scale. |
| Manufacturing | Payments of Supplies (BOMs), High quality Inspection Experiences, Work Orders, Certificates of Evaluation (CoA) | Half Quantity, Amount, Materials Spec, Cross/Fail Standing, Serial Quantity | Enhance high quality management by digitizing inspection studies; speed up manufacturing cycles by automating work order processing; guarantee compliance by verifying materials specs from CoAs. |
Half A: The 4-stage trendy knowledge extraction engine for AI-ready knowledge
The evolution of data extraction from the inflexible, rule-based strategies of the previous to immediately’s adaptive, machine learning-driven programs has made true workflow automation doable. This contemporary workflow consists of 4 important, interconnected levels.
Step 1: Omnichannel ingestion
The objective right here is to cease the countless cycle of guide downloads and uploads by making a single, automated entry level for all incoming paperwork. That is the primary line of protection towards the information fragmentation that plagues many organizations, the place crucial data is scattered throughout completely different programs and inboxes. A strong platform connects on to your current channels, permitting paperwork to move right into a centralized processing queue from sources like:
- A devoted e mail inbox (e.g., invoices@firm.com).
- Shared cloud storage folders (Google Drive, OneDrive, Dropbox).
- A direct API connection out of your different enterprise software program.
Step 2: AI-first knowledge seize
That is the core expertise that distinguishes trendy IDP from outdated Optical Character Recognition (OCR). Legacy OCR depends on inflexible templates, which break the second a vendor adjustments their bill format. AI-first platforms are “template-agnostic.” They’re pre-trained on hundreds of thousands of paperwork and study to determine knowledge fields primarily based on context, very similar to a human would.
This AI-driven strategy is essential for dealing with the complexities of real-world paperwork. As an example, a latest examine discovered that even minor doc skew (in-plane rotation from a crooked scan) “adversely impacts the information extraction accuracy of all of the examined LLMs,” with efficiency for fashions like GPT-4-Turbo dropping considerably past a 35-degree rotation. The finest knowledge extraction software program contains pre-processing layers that robotically detect and proper for skew earlier than the AI even begins extracting knowledge.
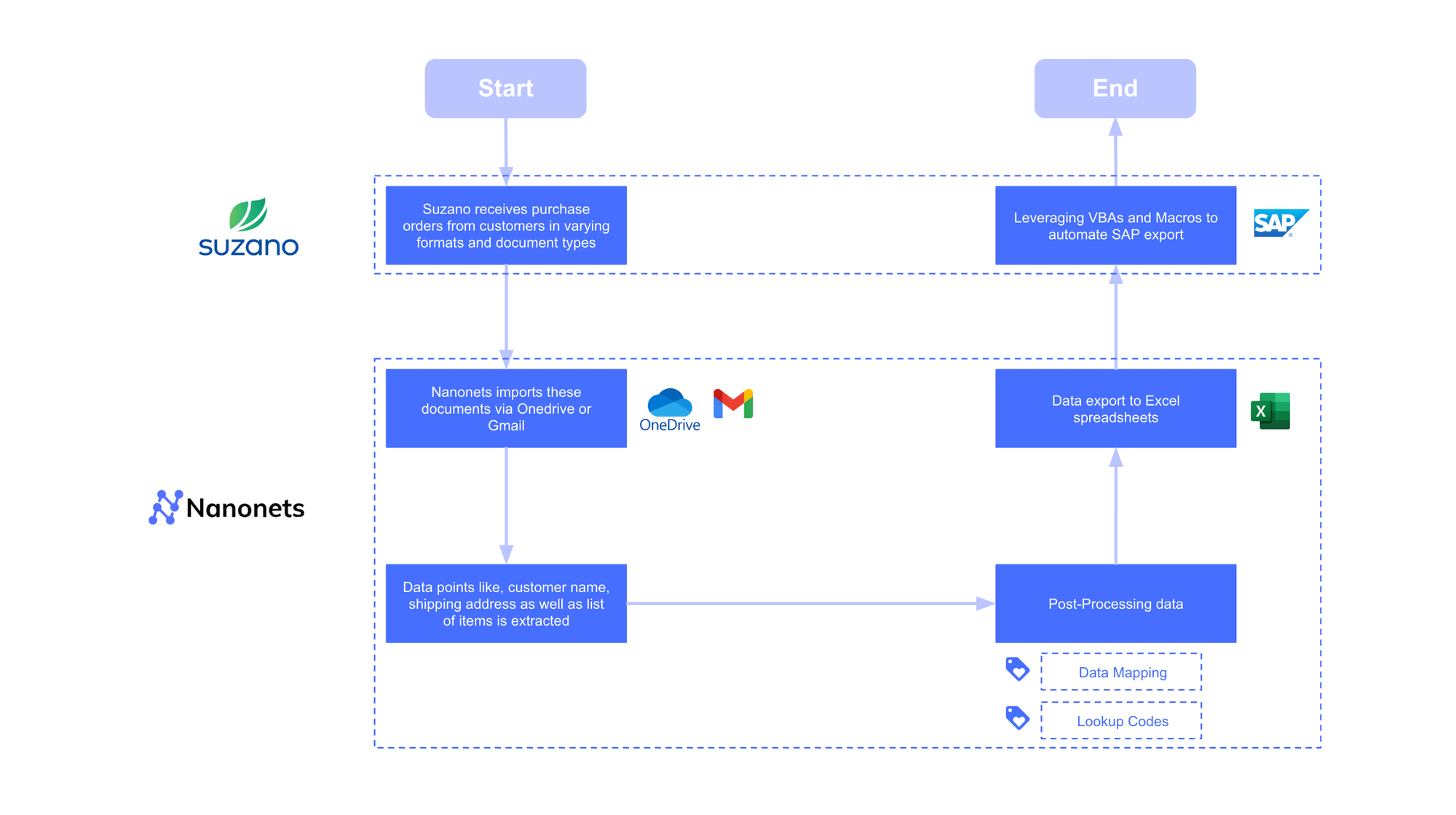
This adaptability is confirmed at scale. Suzano Worldwide processes buy orders from over 70 prospects, every with a singular format. A template-based system would have been unmanageable. By using an AI-driven IDP platform, they effectively dealt with all variations, decreasing their processing time per order by 90%—from 8 minutes to only 48 seconds.
🗨️
~ Cristinel Tudorel Chiriac, Undertaking Supervisor at Suzano.
Step 3: Automated validation and enhancement
Uncooked extracted knowledge will not be business-ready. This stage is the sensible software of the “Human-in-the-Loop” (HIL) precept that tutorial analysis has confirmed is non-negotiable for reaching dependable knowledge from AI programs. One 2024 examine on LLM-based knowledge extraction concluded there’s a “dire want for a human-in-the-loop (HIL) course of” to beat accuracy limitations.
That is what separates a easy “extractor” from an enterprise-grade “processing system.” As an alternative of guide spot-checks, a no-code rule engine can robotically implement your online business logic:
- Inside consistency: Guidelines that verify knowledge inside a single doc. For instance, flagging an bill if subtotal + tax_amount doesn’t equal total_amount.
- Historic consistency: Guidelines that verify knowledge towards previous paperwork. For instance, robotically flagging any bill the place the invoice_number and vendor_name match a doc processed within the final 90 days to stop duplicate funds.
- Exterior consistency: Guidelines that verify knowledge towards your programs of report. For instance, verifying {that a} PO_number on an bill exists in your grasp Buy Order database earlier than routing for cost.
Step 4: Seamless integration and export
The ultimate step is to “shut the loop” and remove the final mile of guide knowledge entry. As soon as the information is captured and validated, the platform should robotically export it into your system of report. With out this step, automation is incomplete and creates a brand new guide process: importing a CSV file.
Main IDP platforms present pre-built, two-way integrations with main ERP and accounting programs, akin to QuickBooks, NetSuite, and SAP, enabling the system to robotically sync payments and replace cost statuses with out requiring human intervention.
Half B: Your 2-week implementation plan
Deploying certainly one of these knowledge extraction options doesn’t require a multi-month IT venture that drains assets and delays worth. With a contemporary, no-code IDP platform, a enterprise group can obtain important automation in a matter of weeks. This part supplies a sensible two-week dash plan to information you from pilot to manufacturing, adopted by an sincere evaluation of the real-world challenges you will need to anticipate for a profitable deployment.
Week 1: Setup, pilot, and fine-tuning
- Setup and pilot: Join your main doc supply (e.g., your AP e mail inbox). Add a numerous batch of no less than 30 historic paperwork from 5-10 completely different distributors. Carry out a one-time verification of the AI’s preliminary extractions. This includes a human reviewing the AI’s output and making corrections, offering essential suggestions to the mannequin in your particular doc sorts.
- Practice and configure: Provoke a mannequin re-train primarily based in your verified paperwork. This fine-tuning course of usually takes 1-2 hours. Whereas the mannequin trains, configure your 2-3 most crucial validation guidelines and approval workflows (e.g., flagging duplicates and routing high-value invoices to a supervisor).
Week 2: Go reside and measure
- Go reside: Start processing your reside, incoming paperwork by way of the now-automated workflow.
- Monitor your key metric: Crucial success metric is your Straight-By means of Processing (STP) Fee. That is the share of paperwork which are ingested, captured, validated, and exported with zero human touches. Your objective must be to attain an STP price of 80% or larger. For reference, the property administration agency Hometown Holdings achieved an 88% STP price after implementing its automated workflow.
Half C: Navigating the real-world implementation challenges
The trail to profitable automation includes anticipating and fixing key operational challenges. Whereas the expertise is strong, treating it as a easy “plug-and-play” answer with out addressing the next points is a standard explanation for failure. That is what separates a stalled venture from a profitable one.
- The issue: The soiled knowledge actuality
- What it’s: Actual-world enterprise paperwork are messy. Scans are sometimes skewed, codecs are inconsistent, and knowledge is fragmented throughout programs. It may well trigger even superior AI fashions to hallucinate and produce incorrect outputs.
- Actionable answer:
- Prioritize a platform with sturdy pre-processing capabilities that robotically detect and proper picture high quality points like skew.
- Create workflows that consolidate associated paperwork earlier than extraction to supply the AI with a whole image.
- The issue: The last-mile integration failure
- What it’s: Many automation initiatives succeed at extraction however fail on the closing, essential step of getting validated knowledge right into a legacy ERP or system of report. This leaves groups caught manually importing CSV information, a bottleneck that negates many of the effectivity features. This difficulty is a number one explanation for venture failure. This difficulty is a number one explanation for venture failure. A BCG report discovered that 65% of digital transformations fail to attain their aims, actually because organizations “underestimate integration complexities”.
- Actionable answer:
- Outline your integration necessities as a non-negotiable a part of your choice course of.
- Prioritize platforms with pre-built, two-way integrations in your particular software program stack (e.g., QuickBooks, SAP, NetSuite).
- The flexibility to robotically sync knowledge is what allows true, end-to-end straight-through processing.
- The issue: The governance and safety crucial
- What it’s: Your doc processing platform is the gateway to your organization’s most delicate monetary, authorized, and buyer knowledge. Connecting inner paperwork to AI platforms introduces new and important safety dangers if not correctly managed. As a 2025 PwC report on AI predicts, rigorous governance and validation of AI programs will grow to be “non-negotiable”.
- Actionable answer:
- Select a vendor with enterprise-grade safety credentials (e.g., SOC 2, GDPR, HIPAA compliance)
- Guarantee distributors have a transparent knowledge governance coverage that ensures your knowledge is not going to be used to coach third-party fashions.
The ROI: From stopping worth leakage to driving revenue
A contemporary doc automation platform will not be a price heart; it is a value-creation engine. The return on funding (ROI) goes far past easy time financial savings, straight impacting your backside line by plugging monetary drains which are typically invisible in guide workflows.
A 2025 McKinsey report identifies that one of the crucial important sources of worth leakage is corporations dropping roughly 2% of their whole spend to points akin to off-contract purchases and unfulfilled provider obligations. Automating and validating doc knowledge is among the most direct methods to stop this.
Right here’s how this seems in observe throughout completely different companies.
Instance 1: 80% value discount in property administration
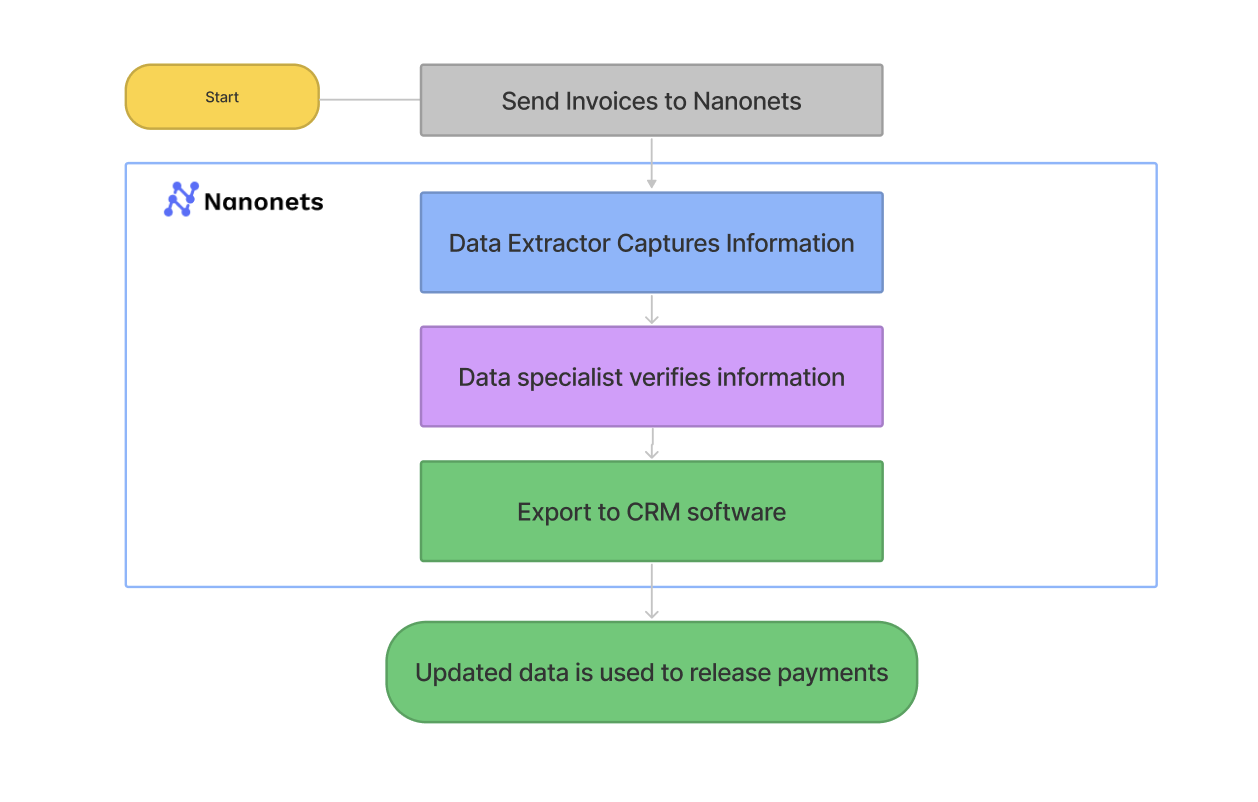
Ascend Properties, a quickly rising property administration agency, noticed its bill quantity develop 5x in 4 years.
- Earlier than: To deal with the quantity manually, their course of would have required 5 full-time workers devoted to only bill verification and entry.
- After: By implementing an IDP platform, they now course of 400 invoices a day in simply 10 minutes with just one part-time worker for oversight.
- The end result: This led to a direct 80% discount in processing prices and saved the work of 4 full-time workers, permitting them to scale their enterprise with out scaling their back-office headcount.
Instance 2: $40,000 enhance in Internet Working Revenue
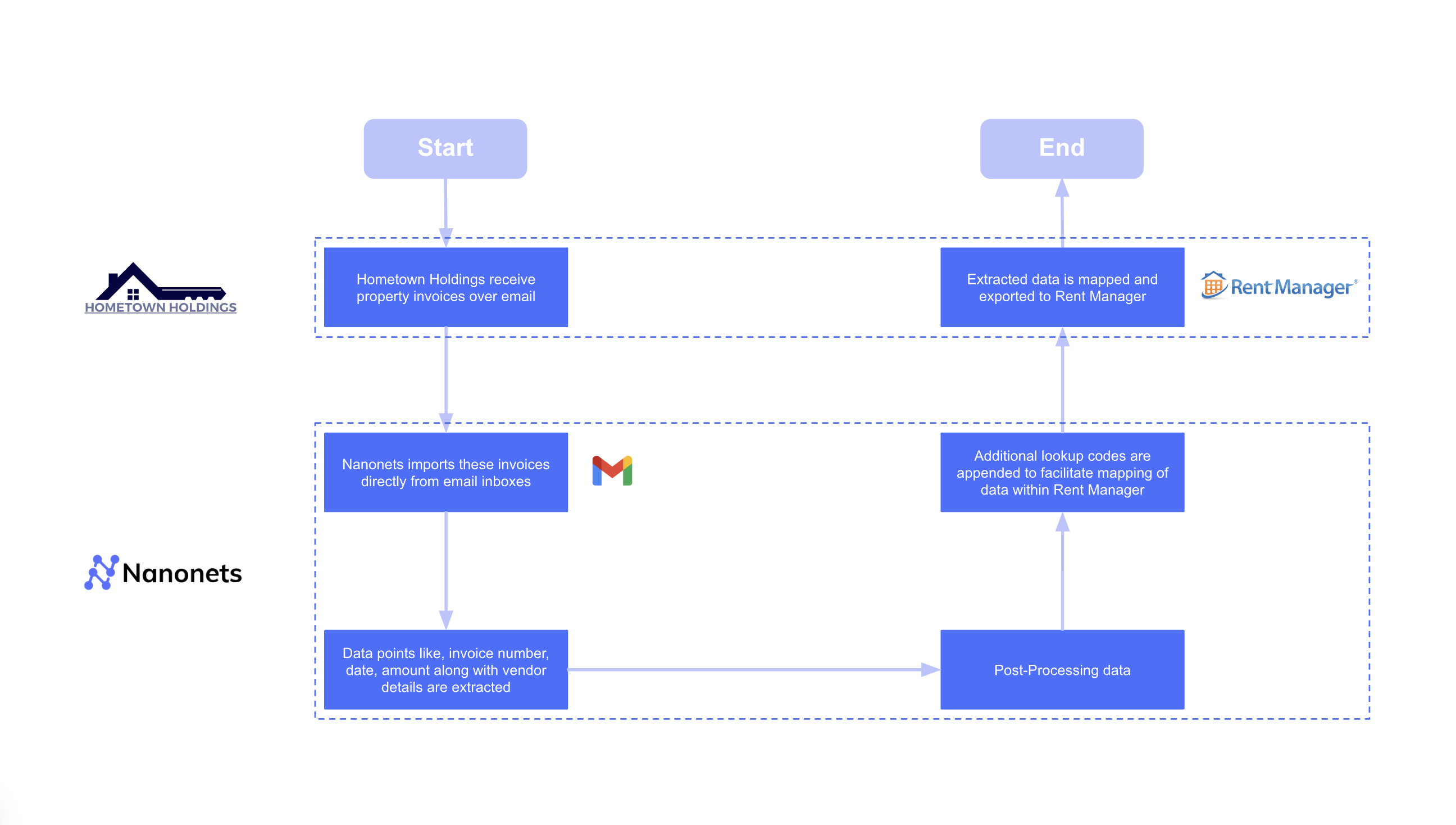
For Hometown Holdings, one other property administration firm, the objective was not simply value financial savings however worth creation.
- Earlier than: Their group spent 4,160 hours yearly manually getting into utility payments into their Lease Supervisor software program.
- After: The automated workflow achieved an 88% Straight-By means of Processing (STP) price, almost eliminating guide entry.
- The end result: Past the huge time financial savings, the elevated operational effectivity and improved monetary accuracy contributed to a $40,000 enhance within the firm’s NOI.
Instance 3: 192 Hours Saved Per Month at enterprise scale
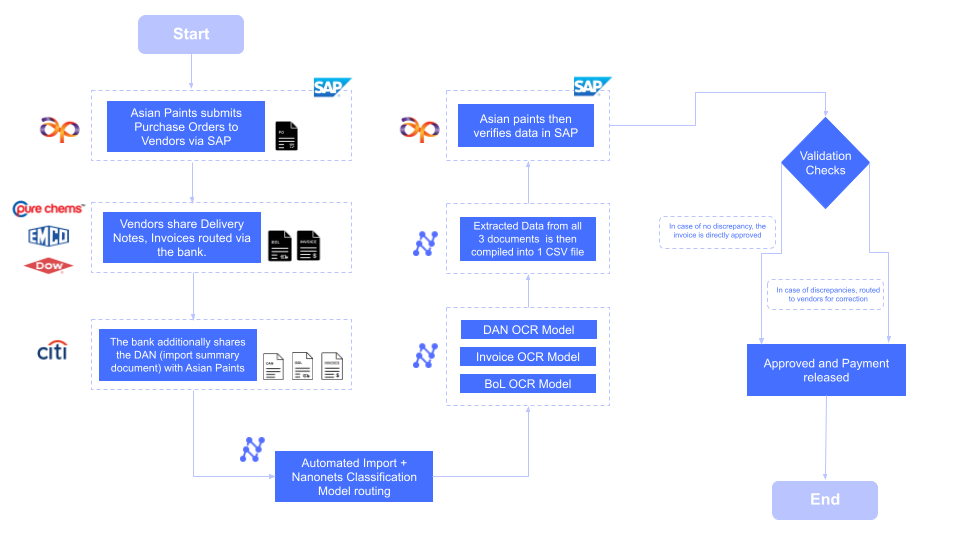
The affect of automation scales with quantity. Asian Paints, certainly one of Asia’s largest paint corporations, manages a community of over 22,000 distributors.
- Earlier than: Processing the advanced set of paperwork for every vendor—buy orders, invoices, and supply notes—took a mean of 5 minutes per doc.
- After: The AI-driven workflow decreased the processing time to ~30 seconds per doc.
- The end result: This 90% discount in processing time saved the corporate 192 person-hours each month, releasing up the equal of a full-time worker to deal with extra strategic monetary duties as an alternative of knowledge entry.
The marketplace for knowledge extraction software program is notoriously fragmented. You can’t group platforms constructed for database replication (ETL/ELT), internet scraping, and unstructured doc processing (IDP) collectively. It creates a big problem when looking for an answer that matches your precise enterprise downside. On this part, we’ll enable you consider completely different knowledge extraction instruments and choose those most fitted in your use case.
We are going to briefly cowl the main platforms for internet and database extraction earlier than analyzing IDP options designed for advanced enterprise paperwork. We may also handle the position of open-source elements for groups contemplating a {custom} “construct” strategy.
a. For software and database Extraction (ETL/ELT)
These platforms are the workhorses for knowledge engineering groups. Their main operate is to maneuver pre-structured knowledge from numerous functions (akin to Salesforce) and databases (like PostgreSQL) right into a central knowledge warehouse for analytics.
1. Fivetran
Fivetran is a totally managed, automated ELT (Extract, Load, Rework) platform identified for its simplicity and reliability. It’s designed to attenuate the engineering effort required to construct and keep knowledge pipelines.
- Professionals:
- Intuitive, no-code interface that accelerates deployment for non-technical groups.
- Its automated schema administration, which adapts to adjustments in supply programs, is a key energy that considerably reduces upkeep overhead.
- Cons:
- Consumption-based pricing mannequin, whereas versatile, can result in unpredictable and excessive prices at scale, a standard concern for enterprise customers.
- As a pure ELT device, all transformations occur post-load within the knowledge warehouse, which may enhance warehouse compute prices.
- Pricing:
- Gives a free plan for low volumes (as much as 500,000 month-to-month lively rows).
- Paid plans observe a consumption-based pricing mannequin.
- Integrations:
- Helps over 500 connectors for databases, SaaS functions, and occasions.
- Key options:
- Totally managed and automatic connectors.
- Automated dealing with of schema drift and normalization.
- Actual-time or near-real-time knowledge synchronization.
Finest use-cases: Fivetran’s main use case is making a single supply of reality for enterprise intelligence. It excels at consolidating knowledge from a number of cloud functions (e.g., Salesforce, Marketo, Google Adverts) and manufacturing databases into a knowledge warehouse, akin to Snowflake or BigQuery.
Ultimate prospects: Information groups at mid-market to enterprise corporations who prioritize velocity and reliability over the price and complexity of constructing and sustaining {custom} pipelines.
2. Airbyte
Airbyte is a number one open-source knowledge integration platform that gives a extremely extensible and customizable various to completely managed options, favored by technical groups who require extra management.
- Professionals:
- Being open-source eliminates vendor lock-in, and the Connector Growth Equipment (CDK) permits builders to construct {custom} connectors shortly.
- It has a big and quickly rising library of over 600 connectors, with a good portion contributed by its neighborhood.
- Cons:
- The setup and administration might be advanced for non-technical customers, and a few connectors could require guide upkeep or {custom} coding.
- Self-hosted deployments might be resource-heavy, particularly throughout giant knowledge syncs. The standard and reliability also can range throughout the numerous community-built connectors.
- Pricing:
- A free and limitless open-source model is out there.
- A managed cloud plan can be accessible, priced per credit score.
- Integrations:
- Helps over 600 connectors, with the flexibility to construct {custom} ones.
- Key options:
- Each ETL and ELT capabilities with non-obligatory in-flight transformations.
- Change Information Seize (CDC) help for database replication.
- Versatile deployment choices (self-hosted or cloud).
Finest use-cases: Airbyte is finest suited to integrating all kinds of knowledge sources, together with long-tail functions or inner databases for which pre-built connectors could not exist. Its flexibility makes it very best for constructing {custom}, scalable knowledge stacks.
Ultimate prospects: Organizations with a devoted knowledge engineering group that values the management, flexibility, and cost-effectiveness of an open-source answer and is provided to handle the operational overhead.
3. Qilk Talend
Qilk Talend is a complete, enterprise-focused knowledge integration and administration platform that gives a set of merchandise for ETL, knowledge high quality, and knowledge governance.
- Professionals:
- Gives in depth and highly effective knowledge transformation and knowledge high quality options that go far past easy knowledge motion.
- Helps a variety of connectors and has versatile deployment choices (on-prem, cloud, hybrid).
- Cons:
- Steep studying curve in comparison with newer, no-code instruments.
- The enterprise version comes with excessive licensing prices, making it much less appropriate for smaller companies.
- Pricing:
- Gives a primary, open-source model. Paid enterprise plans require a {custom} quote.
- Integrations:
- Helps over 1,000 connectors for databases, cloud providers, and enterprise functions.
- Key options:
- Superior ETL/ELT customization.
- Robust knowledge governance instruments (lineage, compliance).
- Open-source availability for core features.
Finest use-cases: Talend is right for large-scale, enterprise knowledge warehousing initiatives that require advanced knowledge transformations, rigorous knowledge high quality checks, and complete knowledge governance.
Ultimate prospects: Massive enterprises, significantly in regulated industries like finance and healthcare, with mature knowledge groups that require a full-featured knowledge administration suite.
b. For internet knowledge extraction (Internet Scraping)
These instruments are for pulling public knowledge from web sites. They are perfect for market analysis, lead era, and aggressive evaluation.
1. Shiny Information
Shiny Information is positioned as an enterprise-grade internet knowledge platform, with its core energy being its huge and dependable proxy community, which is important for large-scale, nameless knowledge assortment.
- Professionals:
- Its in depth community of knowledge facilities and residential IPs permits it to bypass geo-restrictions and sophisticated anti-bot measures.
- The corporate emphasizes a “compliance-first” strategy, offering a degree of assurance for companies involved with the moral and authorized facets of internet knowledge assortment.
- Cons:
- Steep studying curve, with numerous options that may be overwhelming for brand new customers.
- Occasional proxy instability or blockages can disrupt time-sensitive knowledge assortment workflows.
- Pricing:
- Plans are usually subscription-based, with some beginning round $500/month.
- Integrations:
- Primarily integrates by way of a strong API, permitting builders to attach it to {custom} functions.
- Key options:
- Massive datacenter and residential proxy networks.
- Pre-built internet scrapers and different knowledge assortment instruments.
Finest use-cases: Shiny Information is finest for large-scale internet scraping initiatives that require excessive ranges of anonymity and geographic variety. It’s well-suited for duties like e-commerce worth monitoring, advert verification, and gathering public social media knowledge.
Ultimate prospects: The perfect prospects are data-driven corporations, from mid-market to enterprise, which have a steady want for big volumes of public internet knowledge and require a strong and dependable proxy infrastructure to help their operations.
2. Apify
Apify is a complete cloud platform providing pre-built scrapers (known as “Actors”) and the instruments to construct, deploy, and handle {custom} internet scraping and automation options.
- Professionals:
- The Apify Retailer comprises over 2,000 pre-built scrapers, which may considerably speed up initiatives for frequent targets like social media or e-commerce websites.
- The platform is very versatile, catering to each builders who need to construct {custom} options and enterprise customers who can leverage the pre-built Actors.
- Cons:
- The price can escalate for large-scale or high-frequency knowledge operations, a standard concern in person suggestions.
- Whereas pre-built instruments are user-friendly, absolutely using the platform’s {custom} capabilities requires technical data.
- Pricing:
- Gives a free plan with platform credit.
- Paid plans begin at $49/month and scale with utilization.
- Integrations:
- Integrates with Google Sheets, Amazon S3, and Zapier, and helps webhooks for {custom} integrations.
- Key options:
- A big market of pre-built scrapers (“Actors”).
- A cloud setting for creating, working, and scheduling scraping duties.
- Instruments for constructing {custom} automation options.
Finest use-cases: Automating knowledge assortment from e-commerce websites, social media platforms, actual property listings, and advertising instruments. Its flexibility makes it appropriate for each fast, small-scale jobs and sophisticated, ongoing scraping initiatives.
Ultimate prospects: A variety of customers, from particular person builders and small companies utilizing pre-built instruments to giant corporations constructing and managing {custom}, large-scale scraping infrastructure.
3. Octoparse
Octoparse is a no-code internet scraping device designed for non-technical customers. It makes use of a point-and-click interface to show web sites into structured spreadsheets with out writing any code.
- Professionals:
- The visible, no-code interface.
- It may well deal with dynamic web sites with options like infinite scroll, logins, and dropdown menus.
- Gives cloud-based scraping and automated IP rotation to stop blocking.
- Cons:
- Whereas highly effective for a no-code device, it could wrestle with extremely advanced or aggressively protected web sites in comparison with developer-focused options.
- Pricing:
- Gives a restricted free plan.
- Paid plans begin at $89/month.
- Integrations:
- Exports knowledge to CSV, Excel, and numerous databases.
- Additionally presents an API for integration into different functions.
- Key options:
- No-code point-and-click interface.
- Tons of of pre-built templates for frequent web sites.
- Cloud-based platform for scheduled and steady knowledge extraction.
Finest use-cases: Market analysis, worth monitoring, and lead era for enterprise customers, entrepreneurs, and researchers who want to gather structured internet knowledge however do not need coding expertise.
Ultimate prospects: Small to mid-sized companies, advertising companies, and particular person entrepreneurs who want a user-friendly device to automate internet knowledge assortment.
c. For doc knowledge extraction (IDP)
That is the answer to the most typical and painful enterprise problem: extracting structured knowledge from unstructured paperwork. These platforms require specialised AI that understands not solely textual content but additionally the visible format of a doc, making them the best selection for enterprise operators in finance, procurement, and different document-intensive departments.
1. Nanonets
Nanonets is a number one IDP platform for companies that want a no-code, end-to-end workflow automation answer. Its key differentiator is its deal with managing all the doc lifecycle with a excessive diploma of accuracy and suppleness.
- Professionals:
- Manages all the course of from omnichannel ingestion and AI-powered knowledge seize to automated validation, multi-stage approvals, and deep ERP integration, which is a big benefit over instruments that solely carry out extraction.
- The platform’s template-agnostic AI might be fine-tuned to attain very excessive accuracy (over 98% in some circumstances) and constantly learns from person suggestions, making it extremely adaptable to new doc codecs with out guide template creation.
- The system is very versatile and might be programmed for advanced, bespoke use circumstances.
- Cons:
- Whereas it presents a free tier, the Professional plan’s beginning worth could also be a consideration for tiny companies or startups with extraordinarily low doc volumes.
- Pricing:
- Gives a free plan with credit upon sign-up.
- Paid plans are subscription-based per mannequin, with overages charged per area or web page.
- Integrations:
- Gives pre-built, two-way integrations with main ERP and accounting programs like QuickBooks, NetSuite, SAP, and Salesforce.
- Key options:
- AI-powered, template-agnostic OCR that constantly learns.
- A no-code, visible workflow builder for validation, approvals, and knowledge enhancement.
- Pre-trained fashions for frequent paperwork like invoices, receipts, and buy orders.
- Zero-shot fashions that use pure language to explain the information you need to extract from any doc.
Finest use-cases: Automating document-heavy enterprise processes the place accuracy, validation, and integration are crucial. This contains accounts payable automation, gross sales order processing, and compliance doc administration. For instance, Nanonets helped Ascend Properties save the equal work of 4 FTEs by automating their bill processing workflow.
Ultimate prospects: Enterprise groups (Finance, Operations, Procurement) in mid-market to enterprise corporations who want a strong, versatile, and easy-to-use platform to automate their doc workflows with out requiring a devoted group of builders.
2. Rossum
Rossum is a powerful IDP platform with a specific deal with streamlining accounts payable and different document-based processes.
- Professionals:
- Intuitive interface, which is designed to make the method of validating extracted bill knowledge very environment friendly for AP groups.
- Adapts to completely different bill layouts with out requiring templates, which is its core energy.
- Excessive accuracy on customary paperwork.
- Cons:
- Its main deal with AP means it could be much less versatile for a variety of {custom}, non-financial doc sorts in comparison with extra general-purpose IDP platforms.
- Whereas wonderful at extraction and validation, it could provide much less in depth no-code workflow customization for advanced, multi-stage approval processes in comparison with some opponents.
- Pricing:
- Gives a free trial; paid plans are personalized primarily based on doc quantity.
- Integrations:
- Integrates with quite a few ERP programs akin to SAP, QuickBooks, and Microsoft Dynamics.
- Key options:
- AI-powered OCR for bill knowledge extraction.
- An intuitive, user-friendly interface for knowledge validation.
- Automated knowledge validation checks.
Finest use-cases: Automating the extraction and validation of knowledge from vendor invoices for accounts payable groups who prioritize a quick and environment friendly validation expertise.
Ultimate prospects: Mid-market and enterprise corporations with a excessive quantity of invoices who need to enhance the effectivity and accuracy of their AP division.
3. Klippa DocHorizon
Klippa DocHorizon is an AI-powered knowledge extraction platform designed to automate doc processing workflows with a powerful emphasis on safety and compliance.
- Professionals:
- A key differentiator is its deal with safety, with options like doc verification to detect fraudulent paperwork and the flexibility to cross-check knowledge with exterior registries.
- Gives knowledge anonymization and masking capabilities, that are crucial for organizations in regulated industries needing to adjust to privateness legal guidelines like GDPR.
- Cons:
- Documentation might be extra detailed, which can current a problem for growth groups throughout integration.
- Pricing:
- Pricing is out there upon request and is usually personalized for the use case.
- Integrations:
- Integrates with a variety of ERP and accounting programs together with Oracle NetSuite, Xero, and QuickBooks.
- Key options:
- AI-powered OCR with a deal with fraud detection.
- Automated doc classification.
- Information anonymization and masking for compliance.
Finest use circumstances: Processing delicate paperwork the place compliance and fraud detection are paramount, akin to invoices in finance, identification paperwork for KYC processes, and expense administration.
Ultimate prospects: Organizations in finance, authorized, and different regulated industries that require a excessive diploma of safety and knowledge privateness of their doc processing workflows.
4. Tungsten Automation (previously Kofax)
Tungsten Automation supplies an clever automation software program platform that features highly effective doc seize and processing capabilities, typically as a part of a broader digital transformation initiative.
- Professionals:
- Gives a broad suite of instruments that transcend IDP to incorporate Robotic Course of Automation (RPA) and course of orchestration, permitting for true end-to-end enterprise course of transformation.
- The platform is very scalable and well-suited for big enterprises with a excessive quantity and number of advanced, typically international, enterprise processes.
- Cons:
- Preliminary setup might be advanced and should require specialised data or skilled providers. The full value of possession is a big funding.
- Whereas highly effective, it’s typically seen as a heavy-duty IT answer that’s much less agile for enterprise groups who need to shortly construct and modify their very own workflows with out developer involvement.
- Pricing:
- Enterprise pricing requires a {custom} quote.
- Integrations:
- Integrates with a variety of enterprise programs and is usually used as half of a bigger automation technique.
- Key options:
- AP Doc Intelligence and workflow automation.
- Built-in analytics and Robotic Course of Automation (RPA).
- Cloud and on-premise deployment choices.
Finest use circumstances: Massive enterprises trying to implement a broad clever automation technique the place doc processing is a key element of a bigger workflow that features RPA.
Ultimate prospects: Massive enterprises with advanced enterprise processes which are present process a big digital transformation and have the assets to spend money on a complete automation platform.
5. ABBYY
ABBYY is a long-standing chief and pioneer within the OCR and doc seize house, providing a set of highly effective, enterprise-grade IDP instruments like Vantage and FlexiCapture.
- Professionals:
- Extremely correct recognition engine, can deal with an enormous variety of languages and sophisticated paperwork, together with these with cursive handwriting.
- The software program is strong and may deal with a variety of doc sorts with spectacular accuracy, significantly structured and semi-structured varieties.
- It’s engineered for high-volume, mission-critical environments, providing the robustness required by giant, multinational firms for duties like international shared service facilities and digital mailrooms.
- Cons:
- The preliminary setup and configuration generally is a important endeavor, typically requiring skilled providers or a devoted inner group with specialised expertise.
- The full value of possession is on the enterprise degree, making it much less accessible and sometimes prohibitive for small to mid-sized companies that don’t require its full suite of capabilities.
- Pricing:
- Enterprise pricing requires a {custom} quote.
- Integrations:
- Gives a variety of connectors and a strong API for integration with main enterprise programs like SAP, Oracle, and Microsoft.
- Key options:
- Superior OCR and ICR for high-accuracy handwriting extraction.
- Automated doc classification and separation for dealing with advanced, multi-document information.
- A low-code/no-code “talent” designer that enables enterprise customers to coach fashions for {custom} doc sorts.
Finest use circumstances: ABBYY is right for big, multinational firms with advanced, high-volume doc processing wants. This contains digital mailrooms, international shared service facilities for finance (AP/AR), and large-scale digitization initiatives for compliance and archiving.
Ultimate prospects: The perfect prospects are Fortune 500 corporations and enormous authorities companies, significantly in document-intensive sectors like banking, insurance coverage, transportation, and logistics, that require a extremely scalable and customizable platform with in depth language and format help.
6. Amazon Textract
Amazon Textract is a machine studying service that robotically extracts textual content, handwriting, and knowledge from scanned paperwork, leveraging the facility of the AWS cloud.
- Professionals:
- Advantages from AWS’s highly effective infrastructure and integrates seamlessly with all the AWS ecosystem (S3, Lambda, SageMaker), a significant benefit for corporations already on AWS.
- It’s extremely scalable and goes past easy OCR to determine the contents of fields in varieties and knowledge saved in tables.
- Cons:
- It’s a developer-focused API/service, not a ready-to-use enterprise software. Constructing a whole workflow with validation and approvals requires important {custom} growth effort.
- The pay-as-you-go pricing mannequin, whereas versatile, might be difficult to foretell and management for companies with fluctuating doc volumes.
- Pricing:
- Pay-as-you-go pricing primarily based on the variety of pages processed.
- Integrations:
- Deep integration with AWS providers like S3, Lambda, and SageMaker.
- Key options:
- Pre-trained fashions for invoices and receipts.
- Superior extraction for tables and varieties.
- Signature detection and handwriting recognition.
Finest use circumstances: Organizations already invested within the AWS ecosystem which have developer assets to construct {custom} doc processing workflows powered by a scalable, managed AI service.
Ultimate prospects: Tech-savvy corporations and enterprises with sturdy growth groups that need to construct {custom}, AI-powered doc processing options on a scalable cloud platform.
d. Open-Supply elements
For organizations with in-house technical groups contemplating a “construct” strategy for a {custom} pipeline or RAG software, a wealthy ecosystem of open-source elements is out there. These are usually not end-to-end platforms however present the foundational expertise for builders. The panorama might be damaged down into three foremost classes:
1. Foundational OCR engines
These are the basic libraries for the important first step: changing pixels from a scanned doc or picture into uncooked, machine-readable textual content. They don’t perceive the doc’s construction (e.g., the distinction between a header and a line merchandise), however it’s a prerequisite for processing any non-digital doc.
Examples:
- Tesseract: The long-standing, widely-used baseline OCR engine maintained by Google, supporting over 100 languages.
- PaddleOCR: A well-liked, high-performance various that can be famous for its sturdy multilingual capabilities.
2. Structure-aware and LLM-ready conversion libraries
This contemporary class of instruments goes past uncooked OCR. They use AI fashions to grasp a doc’s visible format (headings, paragraphs, tables) and convert all the doc right into a clear, structured format like Markdown or JSON. This output preserves the semantic context and is taken into account “LLM-ready,” making it very best for feeding into RAG pipelines.
Examples:
3. Specialised extraction libraries
Some open-source instruments are constructed to resolve one particular, troublesome downside very properly, making them invaluable additions to a custom-built workflow.
Examples:
- Tabula: A go-to utility, continuously advisable in person boards, for the precise process of extracting knowledge tables from text-based (not scanned) PDFs right into a clear CSV format.
- Stanford OpenIE: A well-regarded tutorial device for a unique form of extraction: figuring out and structuring relationships (subject-verb-object triplets) from sentences of plain textual content.
- GROBID: A highly effective, specialised device for extracting bibliographic knowledge from scientific and tutorial papers.
Shopping for an off-the-shelf product is usually thought of the quickest path to worth, whereas constructing a {custom} answer avoids vendor lock-in however requires a big upfront funding in expertise and capital. The basis explanation for many failed digital transformations is that this “overly simplistic binary selection.” As an alternative, the suitable selection typically relies upon completely on the issue being solved and the group’s particular circumstances.
🗨️
You could marvel why you may’t merely use ChatGPT, Gemini, or another fashions for doc knowledge extraction. Whereas these LLMs are spectacular and do energy trendy IDP programs, they’re finest understood as reasoning engines reasonably than full enterprise options.
Analysis has recognized three crucial gaps that make uncooked LLMs inadequate for enterprise doc processing:
1. Common-purpose fashions wrestle with the messy actuality of enterprise paperwork; even barely crooked scans may cause hallucinations and errors.
2. LLMs lack the structured workflows wanted for enterprise processes, with research exhibiting that they want human validation to attain dependable accuracy.
3. Utilizing public AI fashions for delicate paperwork poses important safety dangers.
Wrapping up: Your path ahead
Automated knowledge extraction is not nearly decreasing guide entry or digitizing paper. The expertise is quickly evolving from a easy operational device right into a core strategic operate. The following wave of innovation is about to redefine how all enterprise departments—from finance to procurement to authorized—entry and leverage their most useful asset: the proprietary knowledge trapped of their paperwork.
Rising developments to look at
- The rise of the “knowledge extraction layer”: As seen in probably the most forward-thinking enterprises, corporations are shifting away from ad-hoc scripts and level options. As an alternative, they’re constructing a centralized, observable knowledge extraction layer. This unified platform handles all forms of knowledge ingestion, from APIs to paperwork, making a single supply of reality for downstream programs.
- From extraction to augmentation (RAG): Essentially the most important development of 2025 is the shift from simply extracting knowledge to utilizing it to reinforce Massive Language Fashions in real-time. The success of Retrieval-Augmented Technology is completely depending on the standard and reliability of this extracted knowledge, making high-fidelity doc processing a prerequisite for reliable enterprise AI.
- Self-healing and adaptive pipelines: The following frontier is the event of AI brokers that not solely extract knowledge but additionally monitor for errors, adapt to new doc codecs with out human intervention, and study from the corrections made through the human-in-the-loop validation course of. This may additional scale back the guide overhead of sustaining extraction workflows.
Strategic affect on enterprise operations
As dependable knowledge extraction turns into a solved downside, its possession will shift. It is going to not be seen as a purely technical or back-office process. As an alternative, it’ll grow to be a enterprise intelligence engine—a supply of real-time insights into money move, contract danger, and provide chain effectivity.
The largest shift is cultural: groups in Finance, Procurement, and Operations will transfer from being knowledge gatherers to knowledge shoppers and strategic analysts. As famous in a latest McKinsey report on the way forward for the finance operate, automation is what permits groups to evolve from “quantity crunching to being a greater enterprise accomplice”.
Key takeaways:
- Readability is step one: The market is fragmented. Choosing the proper device begins with accurately figuring out your main knowledge supply: a web site, a database, or a doc.
- AI readiness begins right here: Excessive-quality, automated knowledge extraction is the non-negotiable basis for any profitable enterprise AI initiative, particularly for constructing dependable RAG programs.
- Deal with the workflow, not simply the device: The most effective options present an end-to-end, no-code workflow—from ingestion and validation to closing integration—not only a easy knowledge extractor.
Closing thought: Your path ahead is to not schedule a dozen demos. It is designed to conduct a easy but highly effective take a look at.
- First, collect 10 of your most difficult paperwork from no less than 5 completely different distributors.
- Then, your first query to any IDP vendor must be: “Can your platform extract the important thing knowledge from these paperwork proper now, with out me constructing a template?”
Their reply, and the accuracy of the reside end result, will inform you the whole lot that you must know. It is going to immediately separate the good, template-agnostic platforms from the inflexible, legacy programs that aren’t constructed for the complexity of recent enterprise.
FAQs
How is knowledge extracted from handwritten paperwork?
Information is extracted from handwriting utilizing a specialised expertise known as Clever Character Recognition (ICR). In contrast to customary OCR, which is educated on printed fonts, ICR makes use of superior AI fashions which were educated on hundreds of thousands of numerous handwriting samples. This permits the system to acknowledge and convert numerous cursive and print types into structured digital textual content, a key functionality for processing paperwork like handwritten varieties or signed contracts.
How ought to a enterprise measure the accuracy of an IDP platform?
Accuracy for an IDP platform is measured at three distinct ranges. First is Discipline-Stage Accuracy, which checks if a single piece of knowledge (e.g., an bill quantity) is appropriate. Second is Doc-Stage Accuracy, which measures if all fields on a single doc are extracted accurately. Crucial enterprise metric, nonetheless, is the Straight-By means of Processing (STP) Fee—the share of paperwork that move from ingestion to export with zero human intervention.
What are the frequent pricing fashions for IDP software program?
The pricing fashions for IDP software program usually fall into three classes: 1) Per-Web page/Per-Doc, a easy mannequin the place you pay for every doc processed; 2) Subscription-Primarily based, a flat price for a set quantity of paperwork monthly or 12 months, which is frequent for SaaS platforms; and 3) API Name-Primarily based, frequent for developer-focused providers like Amazon Textract the place you pay per request. Most enterprise-level plans are custom-quoted primarily based on quantity and complexity.
Can these instruments deal with advanced tables that span a number of pages?
It is a identified, troublesome problem that primary extraction instruments typically fail to deal with. Nevertheless, superior IDP platforms use subtle, vision-based AI fashions to grasp desk buildings. These platforms might be educated to acknowledge when a desk continues onto a subsequent web page and may intelligently “sew” the partial tables collectively right into a single, coherent dataset.
What’s zero-shot knowledge extraction?
Zero-shot knowledge extraction refers to an AI mannequin’s potential to extract a area of knowledge that it has not been explicitly educated to search out. As an alternative of counting on pre-labeled examples, the mannequin makes use of a pure language description (a immediate) of the specified data to determine and extract it. For instance, you possibly can instruct the mannequin to search out the policyholder’s co-payment quantity. This functionality dramatically reduces the time wanted to arrange new or uncommon doc sorts.
How does knowledge residency (e.g., GDPR, CCPA) have an effect on my selection of a knowledge extraction device?
Information residency and privateness are crucial issues. When selecting a device, particularly a cloud-based platform, you will need to guarantee the seller can course of and retailer your knowledge in a particular geographic area (e.g., the EU, USA, or APAC) to adjust to knowledge sovereignty legal guidelines like GDPR. Search for distributors with enterprise-grade safety certifications (like SOC 2 and HIPAA) and a transparent knowledge governance coverage. For optimum management over delicate knowledge, some enterprise platforms additionally provide on-premise or personal cloud deployment choices.

{kind=link}