
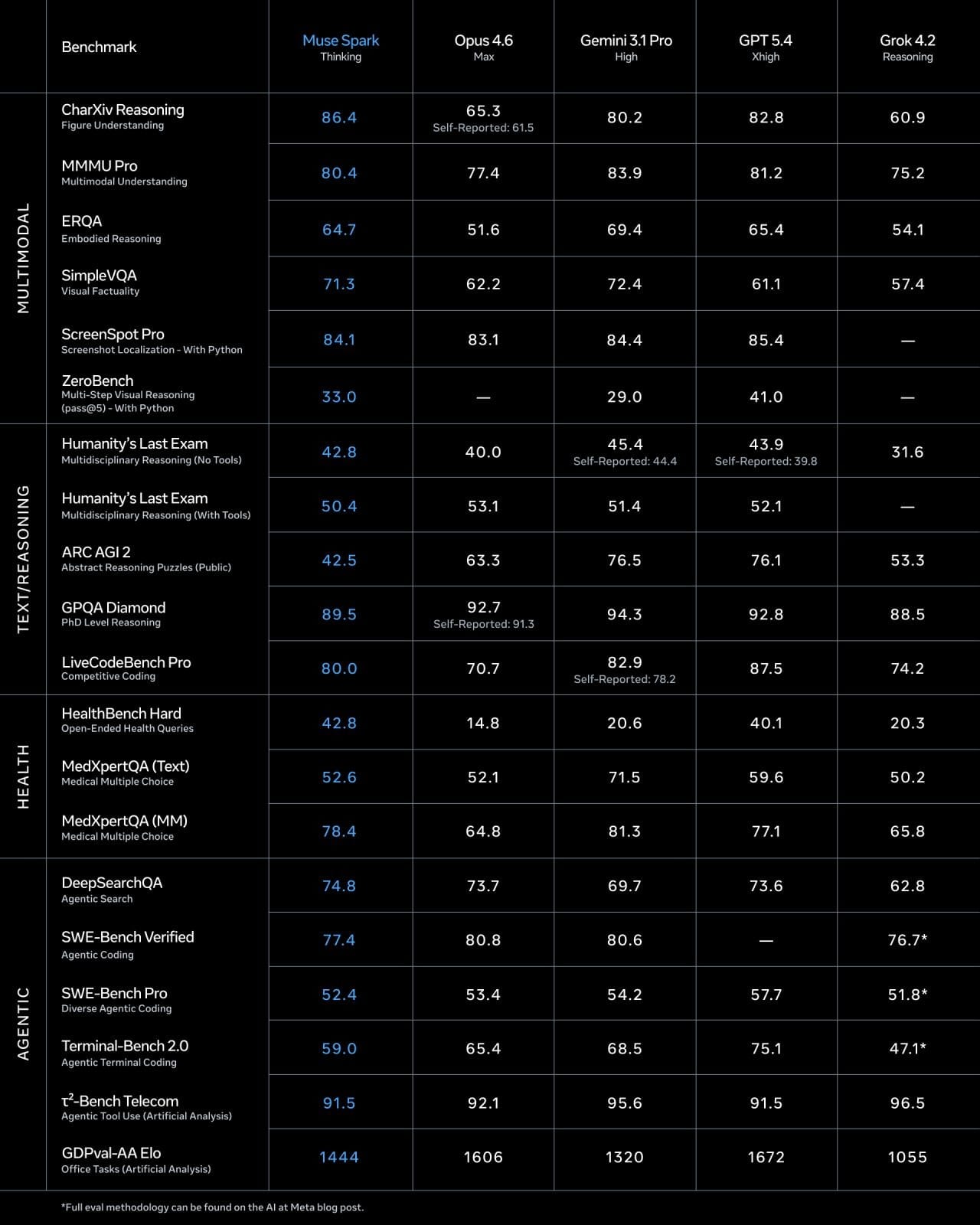
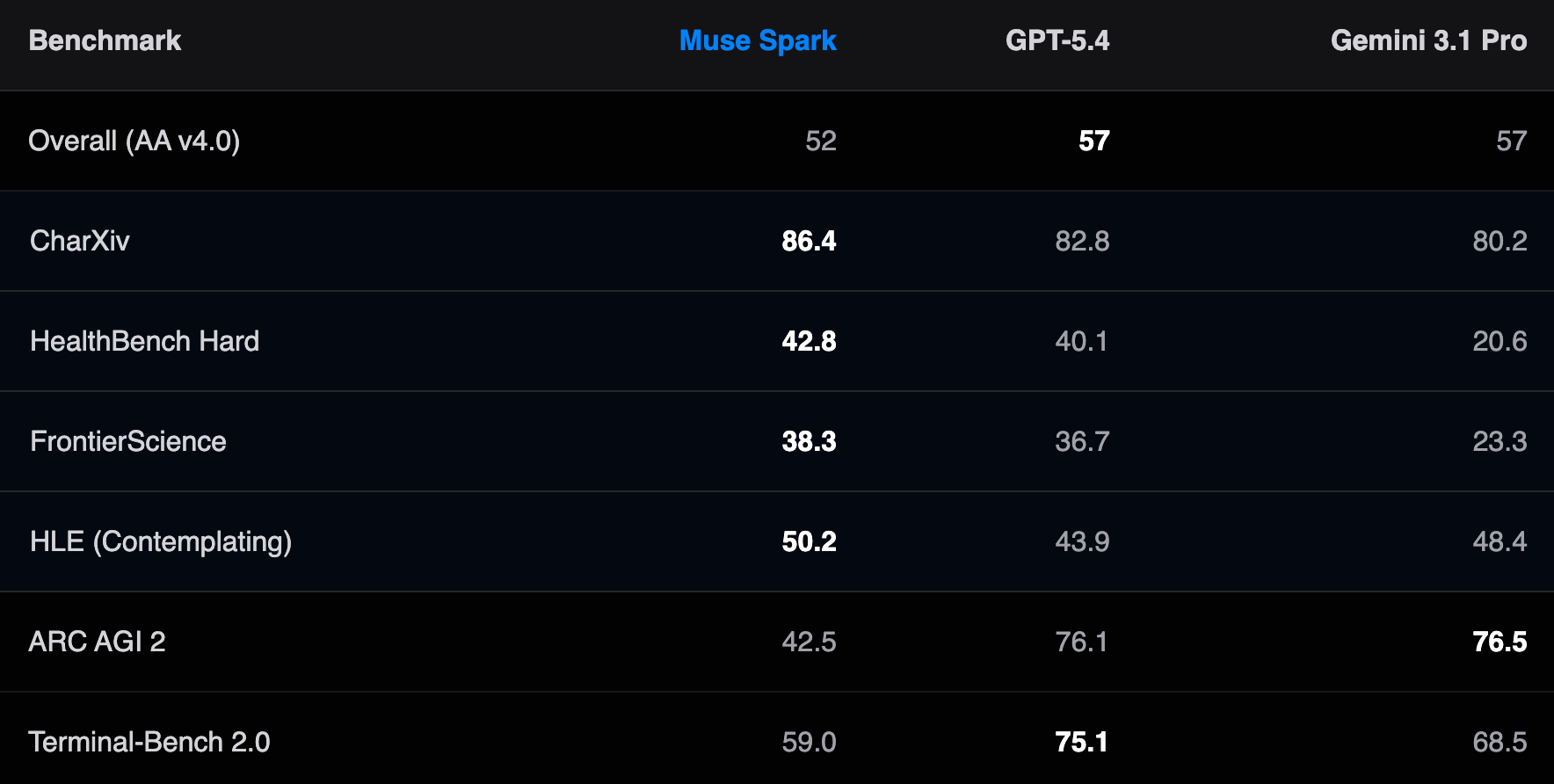
Meta simply launched Muse Spark. The announcement says it beats GPT-5.4 on well being duties, ranks top-five globally on the Synthetic Evaluation Intelligence Index, and scores 89.5% on one thing known as GPQA Diamond.
Eleven months in the past, Meta stated virtually equivalent issues about Llama 4, earlier than folks really used it and the numbers collapsed.
So what are these benchmarks? How do the scores get calculated? And why does a mannequin that tops each leaderboard generally really feel mediocre the second you utilize it?
This information explains what the largest AI benchmarks really measure, together with MMLU, GPQA Diamond, HumanEval, SWE-bench, HealthBench, Humanity’s Final Examination, and Chatbot Area. It additionally explains how benchmark scores are calculated, why some exams matter greater than others, and the way AI labs can inflate benchmark outcomes with out enhancing real-world efficiency.
What Is an AI Benchmark?
A benchmark is only a standardized check. A hard and fast set of questions or duties, given to each AI mannequin in the identical manner, scored the identical manner. The thought is that if everybody takes the identical check, you’ll be able to evaluate the outcomes pretty. However there is a apply the AI group has began calling benchmaxxxing: squeezing each attainable level out of a benchmark by means of analysis selections, cherrypicked settings, and coaching methods that enhance the rating with out essentially enhancing the mannequin.
We’ll get into the specifics of how this works as we undergo every benchmark.
MMLU and MMLU-Professional: The Information Take a look at
What it’s: Over 15,000 multiple-choice questions throughout 57 topics. Regulation, medication, chemistry, historical past, economics, laptop science. 4 reply selections per query.
What an precise query seems like:
A 60-year-old man presents with progressive weak point, hyporeflexia, and fasciculations in each legs. MRI reveals anterior horn cell degeneration. Which of the next is the most definitely analysis? (A) A number of sclerosis (B) Amyotrophic lateral sclerosis (C) Guillain-Barré syndrome (D) Myasthenia gravis
The mannequin outputs a letter. The check runner checks if it matches the reply key.
How the rating is calculated: Earlier than every query, the mannequin is proven 5 instance questions with appropriate solutions, that is known as 5-shot prompting. Then comes the actual query. Rating = appropriate solutions ÷ whole questions, expressed as a proportion.
Why it is almost ineffective in 2026: High fashions now rating above 88% on MMLU. GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Professional are all bunched collectively above 87%. The check can now not separate them, it is like utilizing a rest room scale to measure the load distinction between two folks of comparable construct. Technically attainable, virtually meaningless.
Researchers responded by constructing MMLU-Professional: identical topics, tougher questions, ten reply selections as an alternative of 4, with choices designed to look believable even to educated people. On MMLU-Professional, the gaps between fashions begin displaying up once more.
→ Once you see MMLU in a press launch in 2026, it is principally padding. It is also the benchmark most definitely to be inflated by coaching knowledge contamination: fashions have had three years of web knowledge that overlaps closely with MMLU-style questions.
GPQA Diamond: The Scientific Reasoning Take a look at
That is essentially the most credible tutorial benchmark in use as we speak. The way in which it was constructed is what makes it reliable.
How the questions have been made: Researchers employed PhD scientists in biology, physics, and chemistry. Every scientist wrote a query in their very own area. Then a second PhD scientist in the identical area tried to reply it. If that second skilled acquired it flawed, the query handed the filter. Then three extra folks, good non-domain consultants given limitless web entry and half-hour, tried to reply it. If additionally they failed, the query made it into the Diamond subset.
The outcome: 198 questions that require you to really motive by means of laborious science. You can’t Google them. The solutions aren’t in Wikipedia.
What an precise query seems like:
Two quantum states with energies E1 and E2 have a lifetime of 10⁻⁹ sec and 10⁻⁸ sec, respectively. We wish to clearly distinguish these two vitality ranges. Which of the next might be their vitality distinction to allow them to be clearly resolved? (A) 10⁻⁸ eV (B) 10⁻⁹ eV (C) 10⁻⁴ eV (D) 10⁻¹¹ eV
To reply this, you must know the energy-time uncertainty precept from quantum mechanics, calculate the pure linewidths of the vitality ranges, and verify which vitality distinction is massive sufficient to resolve them. The reply is (A), however you’ll be able to’t discover that by looking. It’s important to derive it.
How the rating is calculated: Identical letter-pick system as MMLU. The mannequin is instructed to motive step-by-step and should finish its response with “ANSWER: LETTER” – capital letters solely. If the mannequin does not observe that precise format, it will get zero for that query no matter whether or not the reasoning was appropriate. This strict formatting rule is intentional: it forces fashions to decide to a particular reply relatively than hedging.
The benchmark in numbers:
- Random guessing: 25% (4 selections)
- Sensible non-experts with web entry: 34%
- PhD-level area consultants: 65%
- GPT-4 when it launched (2023): 39%
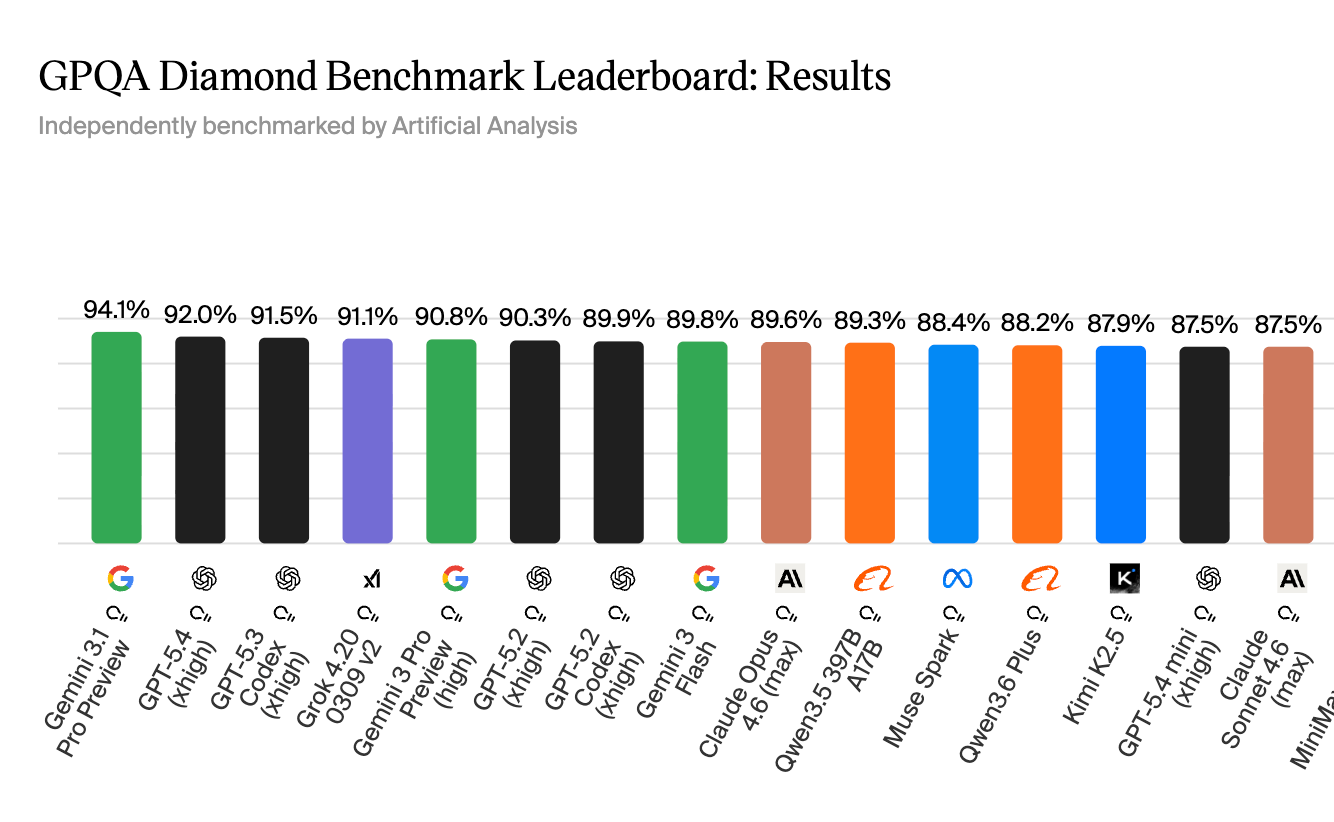
- Muse Spark as we speak: 89.5%
- Gemini 3.1 Professional: 94.3%
- Claude Opus 4.6: 92.8%
That soar from 39% to 89% in three years is actual. These fashions have genuinely gotten higher at scientific reasoning. However Muse Spark remains to be about 5 factors behind Gemini on this check, throughout 198 questions. That is roughly 10 questions. Meta calls this “aggressive” which is technically correct.
HumanEval: The Fundamental Coding Take a look at
What it’s: 164 Python programming issues. Every drawback is a operate signature with a docstring explaining what the operate ought to do.
What an precise query seems like:

The mannequin writes the operate physique. An automatic check runner then executes the code towards 10-15 hidden check circumstances, inputs with recognized appropriate outputs. Both each check case passes, or the issue fails.
How the rating is calculated: The principle metric is cross@1: did the mannequin’s first try cross all of the hidden exams? Rating = variety of issues the place the code labored ÷ 164 whole issues.
Instance of cross vs. fail:
An accurate answer for the above returns “fl” for [“flower”,”flow”,”flight”] and “” for [“dog”,”racecar”,”car”] and handles edge circumstances like an empty record. A mannequin that hardcodes the seen examples however fails on an edge case like a single-element record will get zero for that drawback.
Why it is outdated: High fashions now remedy 90%+ of those 164 issues. They’ve had years to coach on HumanEval-style duties. Researchers overtly query what number of fashions might have seen these precise issues in coaching. Main with HumanEval in 2026 is sort of a automotive firm main their security pitch with a check from 2015.
SWE-bench: The Actual Software program Engineering Take a look at
What it’s: Actual GitHub points from actual open-source repositories. The mannequin is given the problem description and the complete codebase and should produce a code patch (a diff) that fixes the bug.
What an precise activity seems like:
A developer recordsdata a GitHub problem within the sympy math library: “The simplify() operate returns the flawed outcome when known as on expressions containing nested Piecewise objects below sure circumstances.”
The mannequin will get the problem textual content, navigates a codebase with 1000’s of recordsdata, identifies the supply of the bug, and writes a patch. That patch is mechanically utilized to the codebase, and the prevailing check suite runs to verify that the repair works and did not break anything.
How the rating is calculated: Move/fail on the problem stage. Rating = proportion of points the place the mannequin’s patch handed all exams.
Why this benchmark issues greater than HumanEval: As a result of there is no memorization shortcut. The repositories are actual, the bugs are actual, and the analysis atmosphere is strictly managed. You both mounted the bug otherwise you did not.
The place Muse Spark stands right here: Meta’s personal weblog put up acknowledges “present efficiency gaps, particularly in coding workflows.” SWE-bench is nearly actually the place that reveals up. Claude Opus 4.6 at the moment leads most coding evaluations.
Humanity’s Final Examination: The Frontier Reasoning Take a look at
What it’s: Round 2,500 questions written by researchers particularly designed to exceed what present AI can reply: PhD-level and past, throughout math, science, historical past, and legislation.
Why Muse Spark highlights it: In its “Considering” mode, which launches a number of sub-agents working in parallel on totally different components of an issue, Muse Spark scored 50.2%. GPT-5.4 in its highest-effort mode scored 43.9%. Gemini’s Deep Suppose mode scored 48.4%.
That is Muse Spark’s most authentic lead throughout any benchmark. The hole is actual (6+ factors over GPT-5.4) and the benchmark is genuinely laborious. One caveat: Considering mode makes use of considerably extra compute than an ordinary response. You are paying, in time and in API price for that efficiency.
HealthBench: The Medical Reasoning Take a look at
What it’s: Medical and medical reasoning duties evaluated by physicians. Questions cowl affected person symptom interpretation, drug interactions, therapy selections, and well being data accuracy.
How the rating is calculated: Not like automated benchmarks, HealthBench solutions are graded towards physician-defined requirements. The rating represents the proportion of solutions that met scientific accuracy necessities.
The numbers: Muse Spark 42.8%. GPT-5.4 40.1%. Gemini 3.1 Professional 20.6%.
42.8%. GPT-5.4 scored 40.1%. Gemini 3.1 Professional scored 20.6%. That is Muse Spark’s most defensible lead in any benchmark. A 22-point hole over Gemini on a physician-graded check is important.
Chatbot Area: The Human Desire Take a look at
This one is totally different from each different benchmark, and understanding the way it works explains the Llama 4 scandal.
What it exams: Whether or not a human person prefers one mannequin’s response over one other.
The way it works: Two nameless fashions are proven the identical immediate. An actual person reads each responses and picks which one they like. Thousands and thousands of those pairwise comparisons are run. The outcomes feed right into a statistical mannequin known as Bradley-Terry, which converts win/loss information into ELO scores: the identical system used to rank chess gamers.
If Mannequin A beats Mannequin B in 60% of comparisons, Mannequin A will get extra factors. Over time, after sufficient comparisons, the rankings stabilize right into a leaderboard.
Why this benchmark is gameable: Human customers are likely to favor responses which are lengthy, confident-sounding, and well-formatted, even when a shorter, extra correct reply would serve them higher. A mannequin that provides enthusiasm, makes use of daring textual content, and provides elaborately structured responses will rating higher on LMArena than a mannequin that offers a direct, appropriate reply in two sentences.
And that is what occurred with Llama 4.
The Llama 4 Incident
When Meta launched Llama 4 in April 2025, its announcement stated the mannequin ranked #2 on LMArena, simply behind Gemini 2.5 Professional, with an ELO rating of 1417. That quantity was technically correct, however the mannequin that earned that rating was not the one being launched to the general public.
The mannequin Meta submitted to LMArena was known as “Llama-4-Maverick-03-26-Experimental.” Researchers who later in contrast it towards the publicly downloadable model discovered constant behavioral variations:
The experimental model (LMArena): verbose responses, heavy use of emojis, elaborate formatting, dramatic construction, lengthy gildings even for easy questions.
The general public model (what you’d really use): concise, plain, direct, no emojis.
LMArena’s voting system reliably most well-liked the primary model. Actual customers in actual use circumstances most well-liked the second. When the precise public mannequin was individually added to the leaderboard, it ranked thirty second.
There’s one other quantity value figuring out: when LMArena turned on Fashion Management, eradicating the formatting and size benefit, Llama 4 Maverick dropped from 2nd place to fifth. The mannequin’s content material high quality, stripped of its presentational packaging, was a lot much less spectacular.
LMArena said publicly: “Meta’s interpretation of our coverage didn’t match what we anticipate from mannequin suppliers. Meta ought to have made it clearer that ‘Llama-4-Maverick-03-26-Experimental’ was a custom-made mannequin to optimize for human choice.” They up to date their submission guidelines after.
And on ARC-AGI: a benchmark designed to check real novel reasoning, not sample matching, Llama 4 Maverick scored 4.38% on ARC-AGI-1, and 0.00% on ARC-AGI-2. This was by no means within the press launch.
How AI Labs Sport Benchmark Scores: Goodhart’s Regulation and Benchmaxxxing

There is a precept from economics known as Goodhart’s Regulation: when a measure turns into a goal, it stops being an excellent measure.
In plain English: the second everybody agrees that GPQA Diamond is the quantity that issues, labs begin optimizing particularly for GPQA Diamond. Scores go up however the real-world functionality might not transfer in any respect.
This has a reputation within the AI group now: benchmaxxxing. It is the apply of compressing each attainable level out of a benchmark by means of methods that enhance the rating with out essentially enhancing the mannequin. A few of these methods are authentic engineering and a few are nearer to the gaming Meta did with LMArena. The road is genuinely blurry, which is a part of what makes this difficult to name out.
That’s how benchmaxxxing really seems like in apply:
Cherry-picking which benchmarks to publish. Each mannequin will get evaluated on dozens of benchmarks internally. Those that seem within the press launch are those the mannequin did effectively on. The remaining disappear. That is common, each lab does it. Llama 4’s ARC-AGI rating of 0.00% was not within the announcement.
Selecting favorable analysis settings. Many benchmarks may be run in numerous methods: totally different prompting types, totally different numbers of instance questions proven beforehand, totally different temperatures. Labs run all of the variants internally and publish the very best outcome. That is technically allowed however hardly ever disclosed.
Coaching on benchmark-adjacent knowledge. If a benchmark exams quantum mechanics reasoning, you may make certain your coaching set is heavy on quantum mechanics. The questions themselves aren’t within the coaching knowledge, however the data required to reply them is saturated. That is almost unimaginable to tell apart from real functionality enchancment from the surface.
Benchmark contamination, the intense model. Generally precise benchmark questions, or near-identical variants, find yourself in coaching knowledge. This could occur by chance when coaching on web scrapes. It may well additionally occur much less by chance. Susan Zhang, a former Meta AI researcher who later moved to Google DeepMind, shared analysis earlier in 2025 documenting how benchmark datasets may be contaminated by means of coaching corpus overlap. When a mannequin sees the query and reply throughout coaching, it is basically memorized the check. And the rating displays reminiscence, not reasoning.
Majority voting and repeated sampling. Some labs run every benchmark query a number of instances and take the commonest reply. A mannequin that scores 80% on one try would possibly rating 88% throughout 32 makes an attempt. Meta particularly disclosed they do not do that for Muse Spark’s reported numbers, they use zero temperature, single makes an attempt.
The deepest drawback with Goodhart’s Regulation in AI is that it creates a ratchet impact. Every new mannequin must beat the earlier one’s benchmark scores, or it is declared a failure. So each launch will get extra optimized for the benchmarks that exist, which makes these benchmarks much less informative over time, which drives the creation of tougher benchmarks, which then additionally get optimized for. MMLU was the gold commonplace in 2022 nevertheless it’s saturated now. GPQA Diamond changed it.
What Benchmarks Nonetheless Can’t Inform You
Pace. GPQA Diamond says nothing about whether or not the mannequin responds in 1 second or 10.
Price. A mannequin scoring 92% at $15 per million tokens versus one scoring 89% at $1 per million tokens are totally different selections relying on how a lot quantity you are working.
Consistency. A mannequin averaging 90% on a benchmark however producing catastrophically flawed solutions 2% of the time is a distinct danger profile from one which scores 85% uniformly. Benchmarks report averages. Averages conceal tails.
Your particular activity. None of those benchmarks have been designed to your paperwork, your prompts, or your customers. A mannequin that dominates GPQA Diamond would possibly deal with an insurance coverage kind extraction activity worse than a smaller, cheaper mannequin educated on domain-specific knowledge.
Consider AI Fashions for Your Personal Use Case
You possibly can really consider the very best mannequin for you, your self.
Take your ten or twenty most consultant duties: the precise prompts, paperwork, or questions you’d ship to the mannequin in apply. Run each mannequin you are contemplating on these precise inputs. Rating the outputs your self (or have somebody with area experience do it.)
That single customized check will let you know greater than any benchmark desk in a press launch. As a result of benchmarks let you know the place a mannequin claims to face. Your check set tells you the place it really has to point out up.

{kind=link}