
Getting into the Serverless period
On this weblog, we share the journey of constructing a Serverless optimized Artifact Registry from the bottom up. The principle objectives are to make sure container picture distribution each scales seamlessly below bursty Serverless visitors and stays out there below difficult eventualities reminiscent of main dependency failures.
Containers are the fashionable cloud-native deployment format which function isolation, portability and wealthy tooling eco-system. Databricks inner companies have been working as containers since 2017. We deployed a mature and have wealthy open supply mission because the container registry. It labored effectively because the companies have been typically deployed at a managed tempo.
Quick ahead to 2021, when Databricks began to launch Serverless DBSQL and ModelServing merchandise, hundreds of thousands of VMs have been anticipated to be provisioned every day, and every VM would pull 10+ pictures from the container registry. In contrast to different inner companies, Serverless picture pull visitors is pushed by buyer utilization and may attain a a lot increased higher certain.
Determine 1 is a 1-week manufacturing visitors load (e.g. clients launching new knowledge warehouses or MLServing endpoints) that reveals the Serverless Dataplane peak visitors is greater than 100x in comparison with that of inner companies.
Based mostly on our stress checks, we concluded that the open supply container registry couldn’t meet the Serverless necessities.
Serverless challenges
Determine 2 reveals the primary challenges of serving Serverless workloads with open supply container registry:
- Not sufficiently dependable: OSS registries typically have a posh structure and dependencies reminiscent of relational databases, which herald failure modes and huge blast radius.
- Onerous to maintain up with Databricks’ development: within the open supply deployment, picture metadata is backed by vertically scaling relational databases and distant cache cases. Scaling up is gradual, generally takes 10+ minutes. They are often overloaded attributable to under-provisioning or too costly to run when over-provisioned.
- Expensive to function: OSS registries aren’t efficiency optimized and have a tendency to have excessive useful resource utilization (CPU intensive). Operating them at Databricks’ scale is prohibitively costly.
What about cloud managed container registries? They’re typically extra scalable and provide availability SLA. Nonetheless, totally different cloud supplier companies have totally different quotas, limitations, reliability, scalability and efficiency traits. Databricks operates in a number of clouds, we discovered the heterogeneity of clouds didn’t meet the necessities and was too pricey to function.
Peer-to-peer (P2P) picture distribution is one other frequent method to cut back the load to the registry, at a distinct infrastructure layer. It primarily reduces the load to registry metadata however nonetheless topic to aforementioned reliability dangers. We later additionally launched the P2P layer to cut back the cloud storage egress throughput. At Databricks, we consider that every layer must be optimized to ship reliability for the complete stack.
Introducing the Artifact Registry
We concluded that it was needed to construct Serverless optimized registry to satisfy the necessities and guarantee we keep forward of Databricks’ speedy development. We subsequently constructed Artifact Registry – a homegrown multi-cloud container registry service. Artifact Registry is designed with the next ideas:
- Every part scales horizontally:
- Don’t use relational databases; as a substitute, the metadata was endured into cloud object storage (an current dependency for pictures manifest and layers storage). Cloud object storages are far more scalable and have been effectively abstracted throughout clouds.
- Don’t use distant cache cases; the character of the service allowed us to cache successfully in-memory.
- Scaling up/down in seconds: added in depth caching for picture manifests and blob requests to cut back hitting the gradual code path (registry). Consequently, just a few cases (provisioned in a number of seconds) have to be added as a substitute of a whole lot.
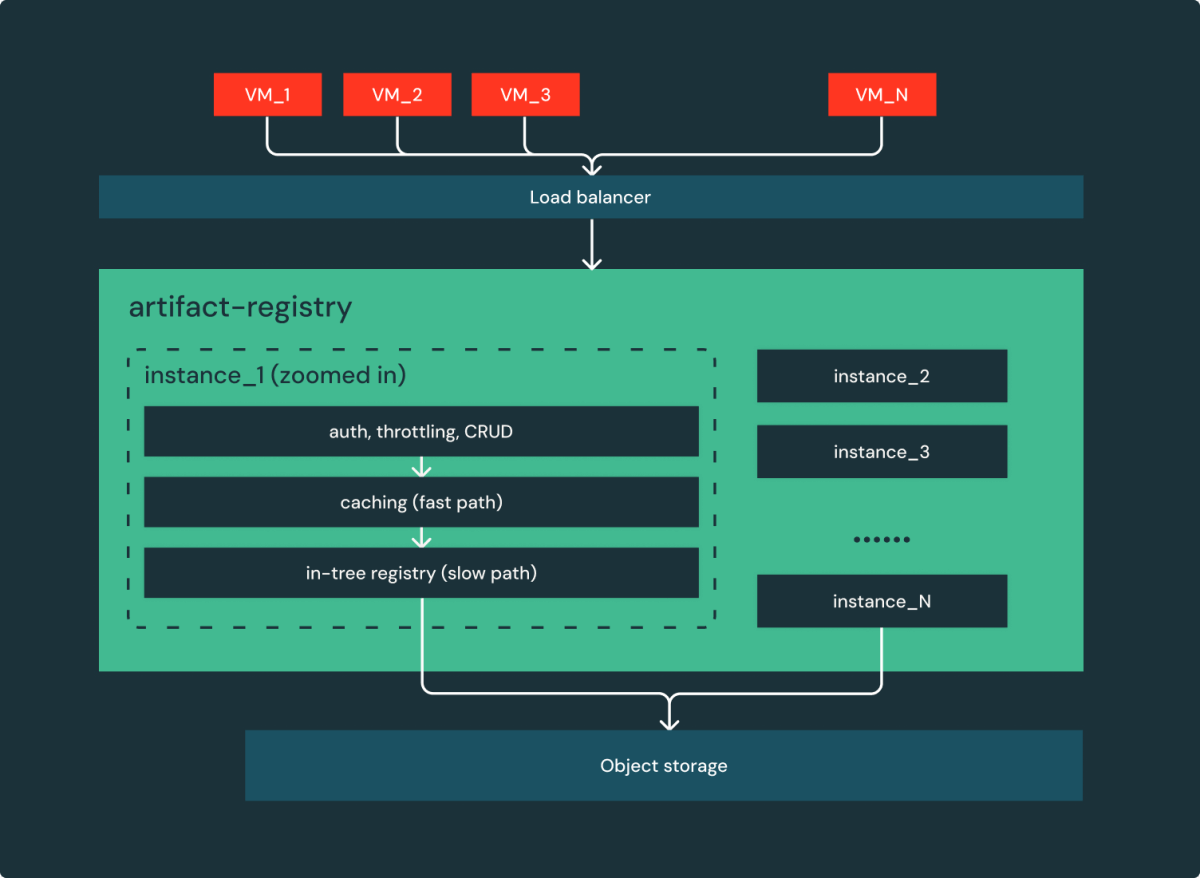
- Easy is dependable: not like OSS, registries are of a number of elements and dependencies, the Artifact Registry embraces minimalism. Behind the load balancer, As proven in Determine 3, there is just one element and one cloud dependency (object storage). Successfully, it’s a easy, stateless, horizontally scalable internet service.
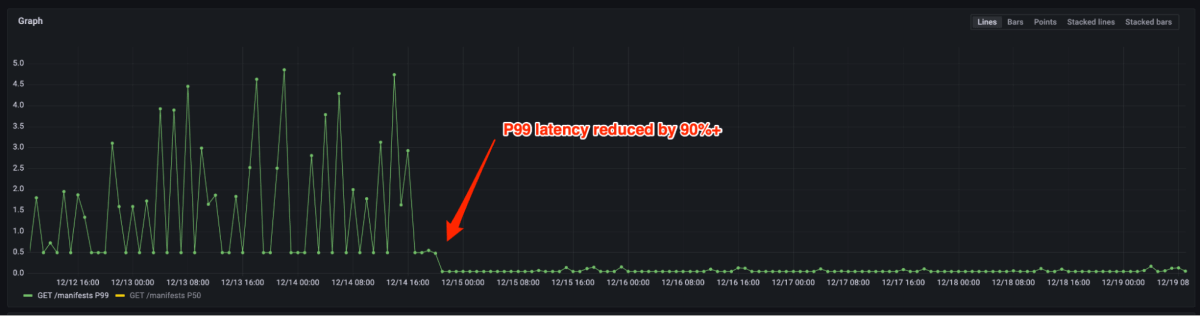
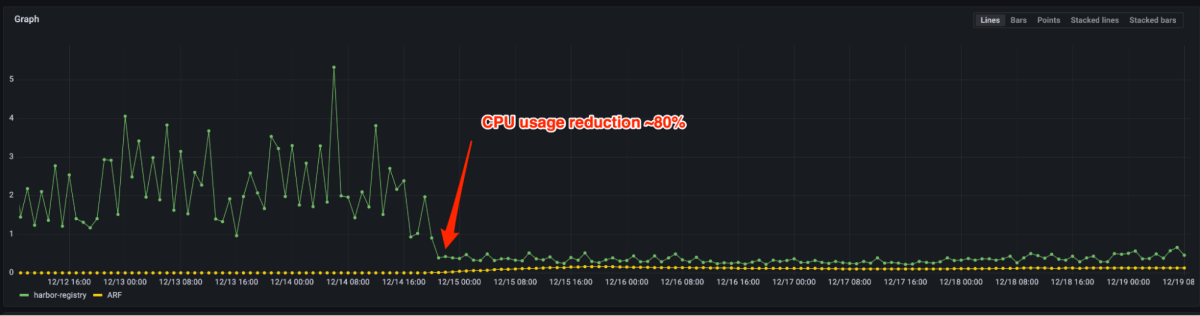
Determine 4 and 5 present that P99 latency diminished by 90%+ and CPU utilization diminished by 80% after migrating from the open supply registry to Artifact Registry. Now we solely must provision a number of cases for a similar load vs. hundreds beforehand. In reality, dealing with manufacturing peak visitors doesn’t require scale out usually. In case auto-scaling is triggered, it may be carried out in a number of seconds.
Surviving cloud object storages outage
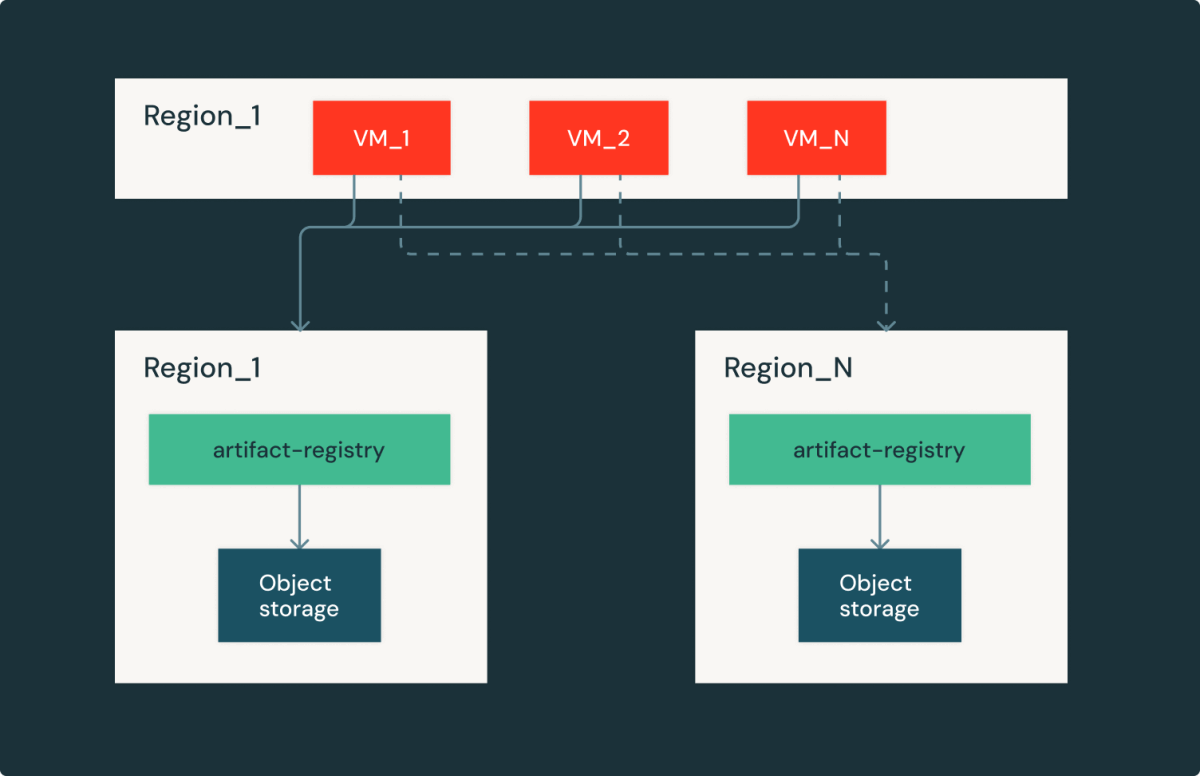
With all of the reliability enhancements talked about above, there may be nonetheless a failure mode that sometimes occurs: cloud object storage outages. Cloud object storages are typically very dependable and scalable; nonetheless, when they’re unavailable (generally for hours), it probably causes regional outages. At Databricks, we attempt arduous to make cloud dependencies failures as clear as attainable.
Artifact Registry is a regional service, an occasion in every cloud/area has an equivalent duplicate. In case of regional storage outages, the picture shoppers are capable of fail over to totally different areas with the tradeoff on picture obtain latency and egress price. By rigorously curating latency and capability, we have been capable of rapidly get well from cloud supplier outages and proceed serving Databricks’ clients.
Conclusions
On this weblog publish, we shared our journey of scaling container registries from serving low churn inner visitors to buyer dealing with bursty Serverless workloads. We purpose-built Serverless optimized Artifact Registry. In comparison with the open supply registry, it diminished P99 latency by 90% and useful resource usages by 80%. To additional enhance reliability, we made the system to tolerate regional cloud supplier outages. We additionally migrated all the prevailing non-Serverless container registries use instances to the Artifact Registry. At this time, Artifact Registry continues to be a stable basis that makes reliability, scalability and effectivity seamless amid Databricks’ speedy development.
Acknowledgement
Constructing dependable and scalable Serverless infrastructure is a group effort from our main contributors: Robert Landlord, Tian Ouyang, Jin Dong, and Siddharth Gupta. The weblog can also be a group work – we admire the insightful evaluations offered by Xinyang Ge and Rohit Jnagal.

{kind=link}