
Companies right this moment deal with a big quantity of queries from prospects, gross sales groups, and inside stakeholders. Manually responding to those queries is a gradual and inefficient course of, usually resulting in delays and inconsistent solutions. A question decision system powered by AI ensures quick, correct, and scalable responses. It really works by retrieving related info and producing exact solutions utilizing Retrieval-Augmented Era (RAG). On this article, I can be sharing with you my journey of constructing a RAG-based question decision system utilizing LangChain, ChromaDB, and CrewAI.
Why Do We Want an AI-powered Question Decision System?
Now, handbook responses take time and will, due to this fact, result in delays. Clients count on immediate replies, and companies want fast entry to correct info. An AI-driven system automates question dealing with, decreasing workload and enhancing consistency. It enhances productiveness, accelerates decision-making, and supplies dependable responses throughout totally different sectors.
An AI-powered question decision system is helpful in buyer assist, the place it automates responses and improves buyer satisfaction. In gross sales and advertising and marketing, it supplies real-time product particulars and buyer insights. Industries like finance, healthcare, schooling, and e-commerce profit from automated question dealing with, guaranteeing clean operations and higher person experiences.
Understanding the RAG Workflow
Earlier than diving into the implementation, let’s first perceive how a Retrieval-Augmented Era (RAG) system works.
The structure consists of three key levels: Indexing, Retrieval, and Era.
1. Constructing a Vector Retailer (Doc Processing & Storage)
The system first processes and shops related paperwork to make them simply searchable. Right here’s how the indexing course of works:
- Paperwork & Chunking: Giant paperwork are damaged into smaller textual content chunks for environment friendly retrieval.
- Embedding Mannequin: These textual content chunks are transformed into vector representations utilizing an AI-based embedding mannequin.
- Vector Retailer: The vectorized information is listed and saved in a database (e.g., ChromaDB) for quick lookup.
2. Question Processing & Retrieval
When a person submits a question, the system retrieves related information earlier than producing a response. Listed below are the steps concerned in question processing and retrieval:
- Person Question Enter: The person submits a query or request.
- Vectorization: The question is transformed right into a numerical vector utilizing the embedding mannequin.
- Search & Retrieval: The system searches for essentially the most related chunks within the vector retailer and retrieves them.
3. Augmentation & Response Era
To generate a well-informed response, the system augments the question with retrieved information. Given under are the steps concerned in response era.
- Increase Question: The retrieved doc chunks are mixed with the unique question.
- LLM Processing: A big language mannequin (LLM) generates a closing response utilizing each the question and the retrieved context.
- Closing Response: The system supplies a factual and context-aware reply to the person.
Now that you know the way RAG programs work, let’s learn to construct a RAG-based question decision system.
Constructing a RAG-based Question Decision System
On this article, I’ll stroll you thru constructing a RAG-based Question Decision System that effectively solutions learner queries utilizing an AI agent. To maintain issues easy, I’ll show a simplified model of the mission and clarify the way it works.
Deciding on the Proper Information for Question Decision
Earlier than constructing a RAG-based question decision system, a very powerful issue to contemplate is information – particularly, the varieties of information required for efficient retrieval. A well-structured data base is crucial, because the accuracy and relevance of responses rely on the standard of the information obtainable. Under are the important thing information varieties that needs to be thought-about for various functions:
- Buyer Assist Information: FAQs, troubleshooting guides, product manuals, and previous buyer interactions.
- Gross sales & Advertising and marketing Information: Product catalogs, pricing particulars, competitor evaluation, and buyer inquiries.
- Inside Information Base: Firm insurance policies, coaching paperwork, and customary working procedures (SOPs).
- Monetary & Authorized Paperwork: Compliance pointers, monetary stories, and regulatory insurance policies.
- Person-Generated Content material: Discussion board discussions, chat logs, and suggestions types that present real-world person queries.
Deciding on the correct information sources was essential for our learner question decision system, to make sure correct and related responses. Initially, I experimented with several types of information to find out which offered the most effective outcomes. First, I used PowerPoint slides (PPTs), however they didn’t yield complete solutions as anticipated. Subsequent, I integrated widespread queries, which improved response accuracy however lacked enough context. Then, I examined previous discussions, which helped in making responses extra related by leveraging earlier learner interactions. Nevertheless, the best method turned out to be utilizing subtitles from course movies, as they offered structured and detailed content material straight associated to learner queries. This method helps in offering fast and related solutions, making it helpful for e-learning platforms and academic assist programs.
Structuring the Question Decision System
Earlier than coding, you will need to construction the Question Decision System. One of the simplest ways to do that is by defining the important thing duties it must carry out.
The system will deal with three important duties:
- Extract and retailer course content material from subtitles (SRT recordsdata).
- Retrieve related course supplies based mostly on learner queries.
- Use an AI-powered agent to generate structured responses.
To realize this, the system is split into three elements, every dealing with a selected operate. This ensures effectivity and scalability.
The system consists of:
- Subtitle Processing – Extracts textual content from SRT recordsdata, processes it, and shops embeddings in ChromaDB.
- Retrieval – Searches and retrieves related course supplies based mostly on learner queries.
- Question Answering Agent – Makes use of CrewAI to generate structured and correct responses.
Every element ensures environment friendly question decision, personalised responses, and clean content material retrieval. Now that now we have our construction, let’s transfer on to implementation.
Implementation Steps
Now that now we have our construction, let’s transfer on to implementation.
1. Importing Libraries
To construct the AI-powered studying assist system, we first have to import important libraries.
import pysrt
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.schema import Doc
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from crewai import Agent, Process, Crew
import pandas as pd
import astLet’s perceive these libraries.
- pysrt – For extracting textual content from SRT subtitle recordsdata.
- langchain.text_splitter.RecursiveCharacterTextSplitter – Splits massive textual content into smaller chunks for higher retrieval.
- langchain.schema.Doc – Represents structured textual content paperwork.
- langchain.embeddings.OpenAIEmbeddings – Converts textual content into numerical vectors for similarity searches.
- langchain.vectorstores.Chroma – Shops embeddings in a vector database for environment friendly retrieval.
- crewai (Agent, Process, Crew) – Defines AI brokers that course of learner queries.
- pandas – Handles structured information within the type of DataFrames.
- ast – Helps in parsing string-based information buildings into Python objects.
- os – Supplies system-level operations like studying surroundings variables.
- tqdm – Shows progress bars throughout long-running duties.
2. Setting Up the Setting
To make use of OpenAI’s API for embeddings, we should load the API key and configure the mannequin settings.
Step 1: Learn the API key from a neighborhood textual content file.
with open('/residence/janvi/Downloads/openai.txt', 'r') as file:
openai_api_key = file.learn()Step 2: Retailer the API key as an surroundings variable so it may be accessed by different elements.
os.environ['OPENAI_API_KEY'] = openai_api_key
Step3: Specify the OpenAI mannequin for use for processing embeddings.
os.environ["OPENAI_MODEL_NAME"] = 'gpt-4o-mini'
By establishing these configurations, we guarantee seamless integration with OpenAI’s API, permitting our system to course of and retailer embeddings effectively.
3. Extracting and Storing Subtitle Information
Subtitles usually include helpful insights from video lectures, making them a wealthy supply of structured content material for AI-based retrieval programs. Extracting and processing subtitle information successfully permits for environment friendly search and retrieval of related info when answering learner queries.
To protect academic insights, we’re utilizing pysrt to learn and preprocess textual content from SRT recordsdata. This ensures the extracted content material is structured and prepared for additional processing and storage..
def extract_text_from_srt(srt_path):
"""Extracts textual content from an SRT subtitle file utilizing pysrt."""
subs = pysrt.open(srt_path)
textual content = " ".be part of(sub.textual content for sub in subs)
return textual contentSince programs could have a number of subtitle recordsdata, we systematically set up and iterate via course supplies saved in predefined folders. This permits for seamless textual content extraction and additional processing.
# Outline course names and their respective folder paths
course_folders = {
"Introduction to Deep Studying utilizing PyTorch": "C:MCodeGAILearn_queriesSubtitle_Introduction_to_Deep_Learning_Using_Pytorch",
"Constructing Manufacturing-Prepared RAG programs utilizing LlamaIndex": "C:MCodeGAILearn_queriesSubtitle of Constructing Manufacturing-Prepared RAG programs utilizing LlamaIndex",
"Introduction to LangChain - Constructing Generative AI Apps & Brokers": "C:MCodeGAILearn_queriesSubtitle_introduction_to_langchain_using_agentic_ai"
}
# Dictionary to retailer course names and their respective .srt file paths
course_srt_files = {}
# Iterate via course folder mappings
for course, folder_path in course_folders.objects():
srt_files = []
# Stroll via the listing to search out .srt recordsdata
for root, _, recordsdata in os.stroll(folder_path):
srt_files.prolong(os.path.be part of(root, file) for file in recordsdata if file.endswith(".srt"))
# Add to dictionary if there are .srt recordsdata
if srt_files:
course_srt_files[course] = srt_filesThis extracted textual content types the muse of our AI-driven studying assist system, enabling superior retrieval and question decision.
Step 2: Storing Subtitles in ChromaDB
On this half, we’ll break down the method of storing course subtitles in ChromaDB, together with textual content chunking, embedding era, persistence, and price estimation.
a. Persistent Listing for ChromaDB
The persist_directory is a folder path the place the saved information can be saved, permitting us to retain embeddings even after restarting this system. With out this, the database would reset after every execution.
persist_directory = "./subtitles_db"
ChromaDB is used as a vector database to retailer and retrieve embeddings effectively.
b. Splitting Textual content into Smaller Chunks
Giant paperwork (like complete course subtitles) exceed token limits for embeddings. To deal with this, we use RecursiveCharacterTextSplitter to interrupt textual content into smaller, overlapping chunks to enhance search accuracy.
# Textual content splitter to interrupt paperwork into smaller chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)Every chunk is 1,000 characters lengthy, guaranteeing that the textual content is damaged into manageable items. To take care of context between chunks, 200 characters from the earlier chunk are included within the subsequent one. This overlap helps protect essential particulars and improves retrieval accuracy.
c. Initializing OpenAI Embeddings and ChromaDB Vector Retailer
We have to convert textual content into numerical vector representations for similarity search. OpenAI’s embeddings permit us to encode our course content material right into a format that may be searched effectively.
# Initialize OpenAI embeddings
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)Right here, OpenAIEmbeddings() initializes the embedding mannequin utilizing our OpenAI API key (openai_api_key). This ensures that each textual content chunk will get transformed right into a high-dimensional vector illustration.
d. Initializing ChromaDB
Now, we retailer these vector embeddings in ChromaDB.
# Initialize Chroma vectorstore with persistent listing
vectorstore = Chroma(
collection_name="course_materials",
embedding_function=embeddings,
persist_directory=persist_directory
)
The collection_name=”course_materials” creates a devoted assortment in ChromaDB to arrange all course-related embeddings. The embedding_function=embeddings specifies OpenAI embeddings for changing textual content into numerical vectors. The persist_directory=persist_directory ensures that every one saved embeddings stay obtainable in ./subtitles_db/, even after restarting this system.
Step 3: Estimating Value of Storing Course Information
Earlier than including paperwork to the vector database, it’s important to estimate the price of token utilization. Since OpenAI expenses per 1,000 tokens, we calculate the anticipated value to handle bills effectively.
a. Defining Pricing Parameters
Since OpenAI expenses per 1,000 tokens, we estimate the fee earlier than including paperwork.
import time
# OpenAI Pricing (modify based mostly on the mannequin getting used)
COST_PER_1K_TOKENS = 0.0001 # Value per 1K tokens for 'text-embedding-ada-002'
TOKENS_PER_CHUNK_ESTIMATE = 750 # Approximate tokens per 1000-character chunk
# Observe whole tokens and price
total_tokens = 0
total_cost = 0
# Begin timing
start_time = time.time()
The COST_PER_1K_TOKENS = 0.0001 defines the fee per 1,000 tokens when utilizing OpenAI embeddings. The TOKENS_PER_CHUNK_ESTIMATE = 750 estimates that every 1,000-character chunk accommodates about 750 tokens. The total_tokens and total_cost variables monitor the entire processed information and price incurred throughout execution. The start_time variable information the beginning time to measure how lengthy the method takes.
b. Checking and Including Programs to ChromaDB
We wish to keep away from reprocessing programs which are already saved within the vector database. So for that we’re querying ChromaDB to examine if the course already exists. If the course is just not discovered, we extract and retailer its subtitle information.
# Add new programs to the vectorstore if they do not exist already
for course, srt_list in course_srt_files.objects():
# Test if the course already exists within the vectorstore
existing_docs = vectorstore._collection.get(the place={"course": course})
if not existing_docs['ids']:
# Course not discovered, add it
srt_texts = [extract_text_from_srt(srt) for srt in srt_list]
course_text = "nnnn".be part of(srt_texts) # Be a part of SRT texts with 4 new traces
doc = Doc(page_content=course_text, metadata={"course": course})
chunks = text_splitter.split_documents([doc])The subtitles are extracted utilizing the extract_text_from_srt() operate. A number of subtitle recordsdata are then joined collectively utilizing nnnn to enhance readability. A Doc object is created, storing the complete subtitle textual content together with its metadata. Lastly, the textual content is break up into smaller chunks utilizing text_splitter.split_documents() for environment friendly processing and retrieval.
c. Estimating Token Utilization and Value
Earlier than including the chunks to ChromaDB, we estimate the fee.
# Estimate value earlier than including paperwork
chunk_count = len(chunks)
batch_tokens = chunk_count * TOKENS_PER_CHUNK_ESTIMATE
batch_cost = (batch_tokens / 1000) * COST_PER_1K_TOKENS
total_tokens += batch_tokens
total_cost += batch_costThe chunk_count represents the variety of chunks generated after splitting the textual content. The batch_tokens estimates the entire variety of tokens based mostly on the chunk depend. The batch_cost calculates the estimated value for processing the present course. The total_tokens and total_cost accumulate values throughout all programs to trace total processing and bills.
d. Including Chunks to ChromaDB
vectorstore.add_documents(chunks)
print(f"Added course: {course} (Chunks: {chunk_count}, Value: ${batch_cost:.4f})")
else:
print(f"Course already exists: {course}")The processed chunks are saved in ChromaDB for environment friendly retrieval. A message is displayed, indicating the variety of chunks added and the estimated processing value.
As soon as all programs are processed, we calculate and show the ultimate outcomes.
# Finish timing
end_time = time.time()
# Show value and time
print(f"nCourse Embeddings Replace Accomplished! 🚀")
print(f"Complete Chunks Processed: {total_tokens // TOKENS_PER_CHUNK_ESTIMATE}")
print(f"Estimated Complete Tokens: {total_tokens}")
print(f"Estimated Value: ${total_cost:.4f}")
print(f"Complete Time Taken: {end_time - start_time:.2f} seconds")
The whole processing time is calculated utilizing (end_time – start_time). The system then shows the variety of chunks processed, the estimated token utilization, and the general value. Lastly, it supplies a abstract of your entire embedding course of.
Output:

From the output, we are able to see {that a} whole of 739 chunks have been processed in 10 seconds, with an estimated value of $0.0554.
4. Querying and Responding to Learner Queries
As soon as the subtitles are saved in ChromaDB, the system wants a solution to retrieve related content material when a learner submits a question. This retrieval course of is dealt with utilizing similarity search, which identifies saved textual content segments that are most related to the enter question.
The way it Works:
- Question Enter: The learner submits a query associated to the course.
- Filtering by Course: The system ensures that retrieval is restricted to the related course materials.
- Similarity Search in ChromaDB: The question is transformed into an embedding, and ChromaDB retrieves essentially the most related saved textual content chunks.
- Returning the High Outcomes: The system selects the highest three most related textual content segments.
- Formatting the Output: The retrieved textual content is formatted and offered as context for additional processing.
# Outline retrieval instrument with metadata filtering
def retrieve_course_materials(question: str, course = course):
"""Retrieves course supplies filtered by course identify."""
filter_dict = {"course": course}
outcomes = vectorstore.similarity_search(question, ok=3, filter=filter_dict)
return "nn".be part of([doc.page_content for doc in results])Instance queries:
course_name = "Introduction to Deep Studying utilizing PyTorch"
query = "What's gradient descent?"
context = retrieve_course_materials(question=query, course= course_name)
print(context)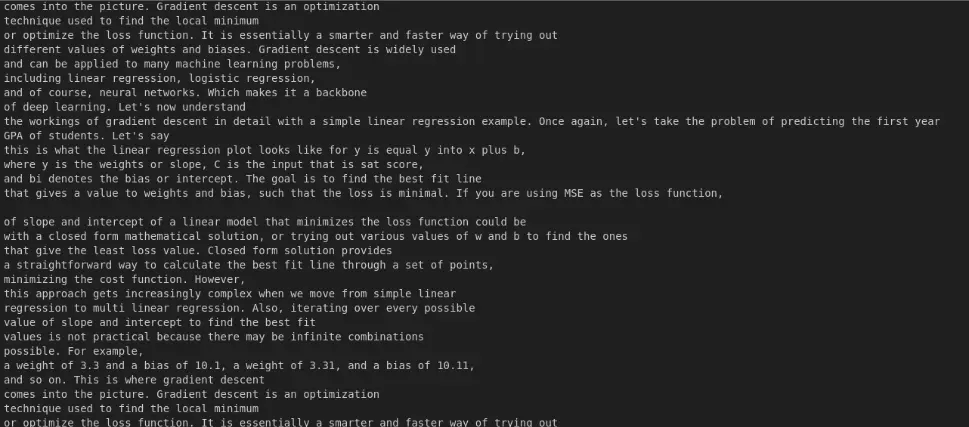
The output consists of the retrieved content material from ChromaDB, filtered by course identify and query, utilizing similarity search to search out essentially the most related info.
Why is Similarity Search Used?
- Semantic Understanding: In contrast to key phrase searches, similarity search finds textual content semantically associated to the question.
- Environment friendly Retrieval: As a substitute of scanning complete paperwork, the system retrieves solely essentially the most related elements.
- Improved Reply High quality: By filtering by course and rating outcomes by relevance, learners obtain extremely focused content material.
This mechanism ensures that when a learner submits a query, they obtain related and contextually correct info from saved course supplies.
5. Implementing the AI Question Answering Agent
As soon as related course materials is retrieved from ChromaDB, the subsequent step is to make use of an AI-powered agent to formulate significant responses to learner queries. CrewAI is used to outline an clever agent answerable for analyzing queries and producing well-structured responses.
Now, let’s see the way it works.
Step 1: Defining the Agent
The question answering agent is created with a transparent function and backstory to information its habits when responding to learner queries.
# Outline the agent with a well-structured function and backstory
query_answer_agent = Agent(
function = "Studying Assist Specialist",
objective = "You assist learners with their queries with the absolute best response",
backstory = """You lead the Learners Question decision division of
an Ed tech firm focussed on self paced programs on matters associated to
Information Science, Machine Studying and Generative AI. You reply to learner
queries associated to course content material, assignments, technical and administrative points.
You might be well mannered, diplomatic and take possession of issues which could possibly be
imporved in your oragnisation.
""",
verbose = False,
)
Let’s perceive what is occurring within the code block. Firstly, we’re offering the function as Studying Assist Specialist for the reason that agent acts as a digital tutor that solutions scholar queries. Then, we outline the objective, guaranteeing that the agent prioritizes accuracy and readability in its responses. Lastly, we set verbose=False, which retains the execution silent until debugging is required. This well-defined agent function ensures that responses are useful, structured, and aligned with the academic platform’s tone.
Step 2: Defining the Process
After defining the agent, we have to assign it a process
query_answering_task = Process(
description= """
Reply the learner queries to the most effective of your skills. Attempt to maintain your response concise with lower than 100 phrases.
Right here is the question: {question}
Right here is analogous content material from the course extracted from subtitles, which you must use solely when required: {relevant_content} .
Since this content material is extracted from course subtitles, there could also be spelling errors, be certain to right these, whereas utilizing this info in your response.
There could also be some earlier dialogue with the learner on this thread. Right here is the python record of previous discussions: {thread} .
On this thread, the content material which begins with 'learner' is the query by the coed and the content material which begins with 'assist'
is the response given by you. Use this previous dialogue appropriatly to come back with an important reply.
That is the complete identify of the learner: {learner_name}
Handle every learner by their first identify, if you're unsure what the primary identify is, merely begin with Hello.
Additionally point out some applicable and inspiring comforting traces on the finish of the reponse, like "hope you discovered this beneficial",
"I hope this info is helpful. Sustain the good work!", "Glad to help! Be at liberty to succeed in out anytime." and so forth.
If you're unsure concerning the reply point out - "Sorry, I'm not certain about this, I'll get again to you"
""",
expected_output = "A crisp correct response to the question",
agent=query_answer_agent)
Let’s break down the duty offered to the AI agent. The question dealing with includes processing {question}, which represents the learner’s query. The response needs to be concise (beneath 100 phrases) and correct. When utilizing course content material, {relevant_content} is extracted from subtitles saved in ChromaDB, and the AI should right any spelling errors earlier than together with the content material in its response.
If previous discussions exist, {thread} helps keep continuity. Learner queries begin with “learner”, whereas previous responses start with “assist”, permitting the agent to supply context-aware solutions. Personalization is achieved utilizing {learner_name}—the agent addresses college students by their first identify or defaults to “Hello” if unsure.
To make responses extra partaking, the AI provides a constructive closing assertion, comparable to “Hope you discovered this beneficial!” or “Be at liberty to succeed in out anytime.” If the AI is not sure about a solution, it explicitly states: “Sorry, I’m not certain about this, I’ll get again to you.” This method ensures politeness, readability, and a structured response format, enhancing learner engagement and belief.
Step 3: Initializing the CrewAI Occasion
Now that now we have each the agent and the duty, we initialize CrewAI, which permits the agent to course of queries dynamically.
# Create the Crew
response_crew = Crew(
brokers=[query_answer_agent],
duties=[query_answering_task],
verbose=False
)
The brokers=[query_answer_agent] parameter provides the Studying Assist Specialist agent to the crew. The duties=[query_answering_task] assigns the question answering process to this agent. Setting verbose=False retains the output minimal until debugging is required. CrewAI permits the system to course of a number of learner queries concurrently, making it scalable and environment friendly for dynamic question dealing with.
Why Use CrewAI for Question Answering?
- Structured Responses: Ensures that every response is well-organized and informative.
- Context Consciousness: Makes use of retrieved course materials and previous discussions to enhance response high quality.
- Scalability: Can deal with a number of queries dynamically by processing them as duties inside CrewAI.
- Effectivity: Reduces response time by streamlining the question decision workflow.
By implementing this AI-powered answering system, learners obtain well-informed responses tailor-made to their particular queries.
Step 4: Producing Responses for A number of Learner’s Queries
As soon as the AI agent is about up, it must dynamically course of learner queries saved in a structured dataset.
The under code processes learner queries saved in a CSV file and generates responses utilizing an AI agent. It first masses the dataset containing learner queries, course particulars, and dialogue threads. The reply_to_query operate extracts related particulars just like the learner’s identify, course identify, and present question. If earlier discussions exist, they’re retrieved for context. If the question accommodates a picture, it’s skipped. The operate then fetches associated course supplies from ChromaDB and sends the question, related content material, and previous discussions to the AI agent for producing a structured response.
df = pd.read_csv(filepath_or_buffer="C:MCodeGAILearn_queries/filtered_data_top3_courses.csv")
def reply_to_query(df_new=df_new, index=1):
learner_name = df_new.iloc[index]["thread_starter"]
course_name = df_new.iloc[index]["course"]
if df_new.iloc[index]['number_of_replies']>1:
thread = ast.literal_eval(df_new.iloc[index]["modified_thread"])
else:
thread = []
query = df_new.iloc[index]["current_query"]
if df_new.iloc[index]['has_image'] == True:
return " "
context = retrieve_course_materials(question = query , course=course_name)
response_result = response_crew.kickoff(inputs={"question": query, "relevant_content": context, "thread": thread, "learner_name": learner_name})
print('Q: ', query)
print('n')
print('A: ', response_result)
print('nn')Testing the operate, it’s executed for one question (index=1)
reply_to_query(df, index=1)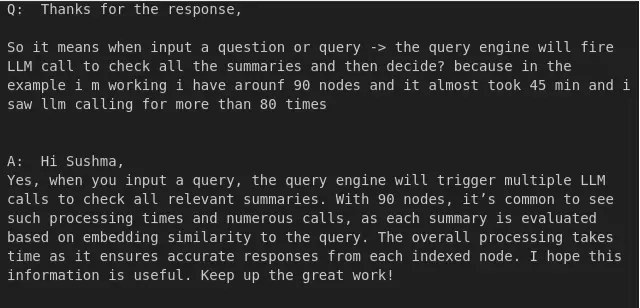
From this we are able to see that it really works positive only for one index.
Now, iterating via all queries, processing each whereas dealing with potential errors. This ensures environment friendly automation of question decision, permitting a number of learner queries to be processed dynamically.
for i in vary(len(df)):
strive:
reply_to_query(df, index=i)
besides:
print("Error in index quantity: ", i)
proceedWhy is This Step Necessary?
- Automates Question Processing: The system can deal with a number of learner queries effectively.
- Ensures Contextual Relevance: Responses are generated based mostly on retrieved course supplies and previous discussions.
- Scalability: The strategy permits the AI agent to course of and reply to hundreds of queries dynamically.
- Improved Studying Assist: Learners obtain personalised, data-driven responses to their queries.
This step ensures that each learner question is analyzed, contextualized, and answered successfully, enhancing the general studying expertise.
Output:
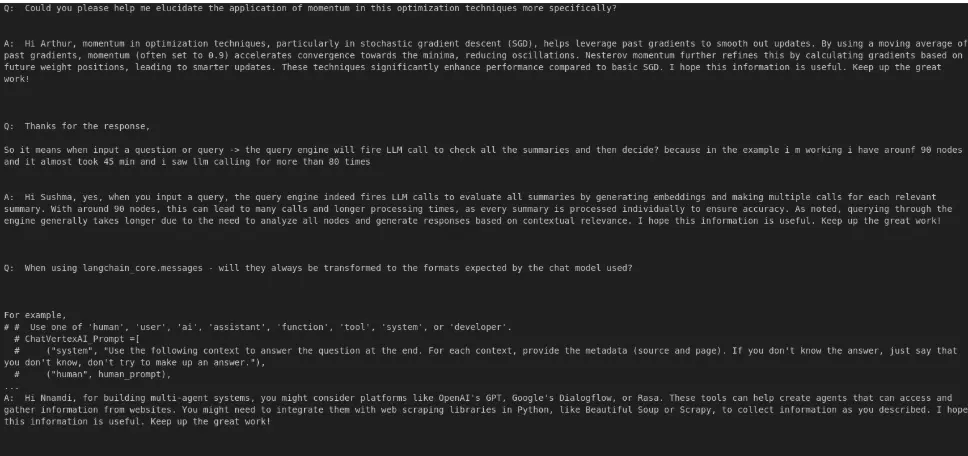
From the output we are able to see that the method of replying to the question has turn into automated adopted by query after which reply.
Future Enhancements
To improve the RAG-Primarily based Question Decision System, a number of enhancements could be made:
- Widespread Questions and Their Options: Implementing a structured FAQ system throughout the question decision framework will assist in offering immediate solutions to incessantly requested questions, decreasing dependency on reside assist.
- Picture Processing Skill: Including the potential to research and extract related info from pictures (comparable to screenshots, charts, or scanned paperwork) will improve the system’s versatility, making it extra helpful in academic and buyer assist domains.
- Bettering the Picture Column Boolean: Refining the logic behind the picture column detection to appropriately establish and course of image-based queries with better accuracy.
- Semantic Chunking and Totally different Chunking Strategies: Experimenting with varied chunking methods, comparable to semantic chunking, fixed-length segmentation, and hybrid approaches, can enhance retrieval accuracy and contextual understanding of responses.
Conclusion
This RAG-Primarily based Question Decision System leverages LangChain, ChromaDB, and CrewAI to automate learner assist effectively. It extracts subtitles, shops them as embeddings in ChromaDB, and retrieves related content material utilizing similarity search. A CrewAI agent processes queries, references previous discussions, and generates structured responses, guaranteeing accuracy and personalization.
The system enhances scalability, retrieval effectivity, and response high quality, making self-paced studying extra interactive. Future enhancements embody multi-modal assist, higher retrieval optimization, and enhanced response era. By automating question decision, this method streamlines studying assist, offering learners with sooner, context-aware responses and enhancing total engagement.
Regularly Requested Questions
A. LangChain is a framework for constructing functions powered by language fashions (LLMs). It helps in processing, retrieving, and producing responses from text-based information. On this mission, LangChain is used for splitting textual content into chunks, producing embeddings, and retrieving course supplies effectively.
A. ChromaDB is a vector database designed for storing and retrieving embeddings. It converts course supplies into numerical representations, permitting similarity-based searches to search out related content material when a learner submits a question.
A. CrewAI permits the creation of AI brokers that deal with duties dynamically. On this mission, it powers a Studying Assist Specialist agent that retrieves course supplies, processes previous discussions, and generates structured responses for learner queries.
A. OpenAI embeddings convert textual content into numerical vectors, making it simpler to carry out similarity searches. This helps in effectively retrieving related course supplies based mostly on a learner’s question.
A. The system makes use of pysrt to extract textual content from subtitle (SRT) recordsdata. The extracted content material is then chunked, embedded utilizing OpenAI embeddings, and saved in ChromaDB for retrieval when wanted.
A. Sure, the system is scalable and might course of a number of learner queries dynamically utilizing CrewAI’s process administration. This ensures fast and environment friendly responses.
A. Future enhancements embody multi-modal assist for pictures and movies, higher retrieval optimization, and improved response era methods to supply much more correct and contextual solutions.
Hello, I’m Janvi, a passionate information science fanatic at present working at Analytics Vidhya. My journey into the world of information started with a deep curiosity about how we are able to extract significant insights from advanced datasets.
Login to proceed studying and luxuriate in expert-curated content material.

{kind=link}