
[ad_1]
ChatGPT one thing like: “Please scout all of tech for me and summarize tendencies and patterns primarily based on what you suppose I’d be inquisitive about,” you already know that you just’d get one thing generic, the place it searches just a few web sites and information sources and arms you these.
It’s because ChatGPT is constructed for basic use instances. It applies regular search strategies to fetch data, usually limiting itself to some net pages.
This text will present you easy methods to construct a distinct segment agent that may scout all of tech, mixture tens of millions of texts, filter knowledge primarily based on a persona, and discover patterns and themes you’ll be able to act on.
The purpose of this workflow is to keep away from sitting and scrolling by boards and social media by yourself. The agent ought to do it for you, grabbing no matter is beneficial.

We’ll be capable of pull this off utilizing a novel knowledge supply, a managed workflow, and a few immediate chaining methods.

By caching knowledge, we will maintain the associated fee down to some cents per report.
If you wish to attempt the bot with out booting it up your self, you’ll be able to be part of this Discord channel. You’ll discover the repository right here if you wish to construct it by yourself.
This text focuses on the overall structure and easy methods to construct it, not the smaller coding particulars as yow will discover these in Github.
Notes on constructing
Should you’re new to constructing with brokers, you would possibly really feel like this one isn’t groundbreaking sufficient.
Nonetheless, if you wish to construct one thing that works, you have to to use various software program engineering to your AI purposes. Even when LLMs can now act on their very own, they nonetheless want steering and guardrails.
For workflows like this, the place there’s a clear path the system ought to take, it is best to construct extra structured “workflow-like” methods. In case you have a human within the loop, you’ll be able to work with one thing extra dynamic.
The rationale this workflow works so nicely is as a result of I’ve an excellent knowledge supply behind it. With out this knowledge moat, the workflow wouldn’t be capable of do higher than ChatGPT.
Making ready and caching knowledge
Earlier than we will construct an agent, we have to put together an information supply it may faucet into.
One thing I believe lots of people get fallacious once they work with LLM methods is the assumption that AI can course of and mixture knowledge solely by itself.
Sooner or later, we would be capable of give them sufficient instruments to construct on their very own, however we’re not there but by way of reliability.
So once we construct methods like this, we’d like knowledge pipelines to be simply as clear as for every other system.
The system I’ve constructed right here makes use of an information supply I already had accessible, which suggests I perceive easy methods to train the LLM to faucet into it.
It ingests 1000’s of texts from tech boards and web sites per day and makes use of small NLP fashions to interrupt down the principle key phrases, categorize them, and analyze sentiment.
This lets us see which key phrases are trending inside totally different classes over a particular time interval.
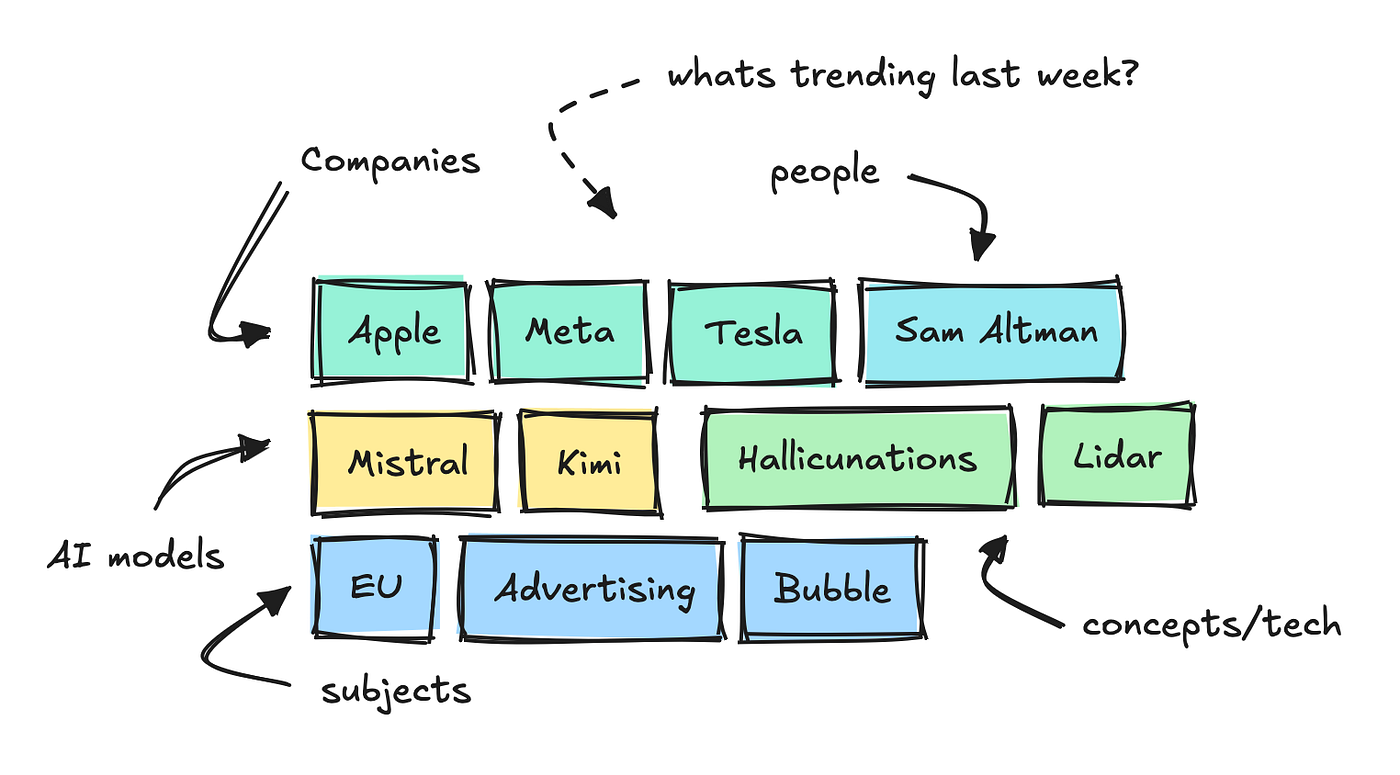
To construct this agent, I added one other endpoint that collects “details” for every of those key phrases.
This endpoint receives a key phrase and a time interval, and the system types feedback and posts by engagement. Then it course of the texts in chunks with smaller fashions that may determine which “details” to maintain.
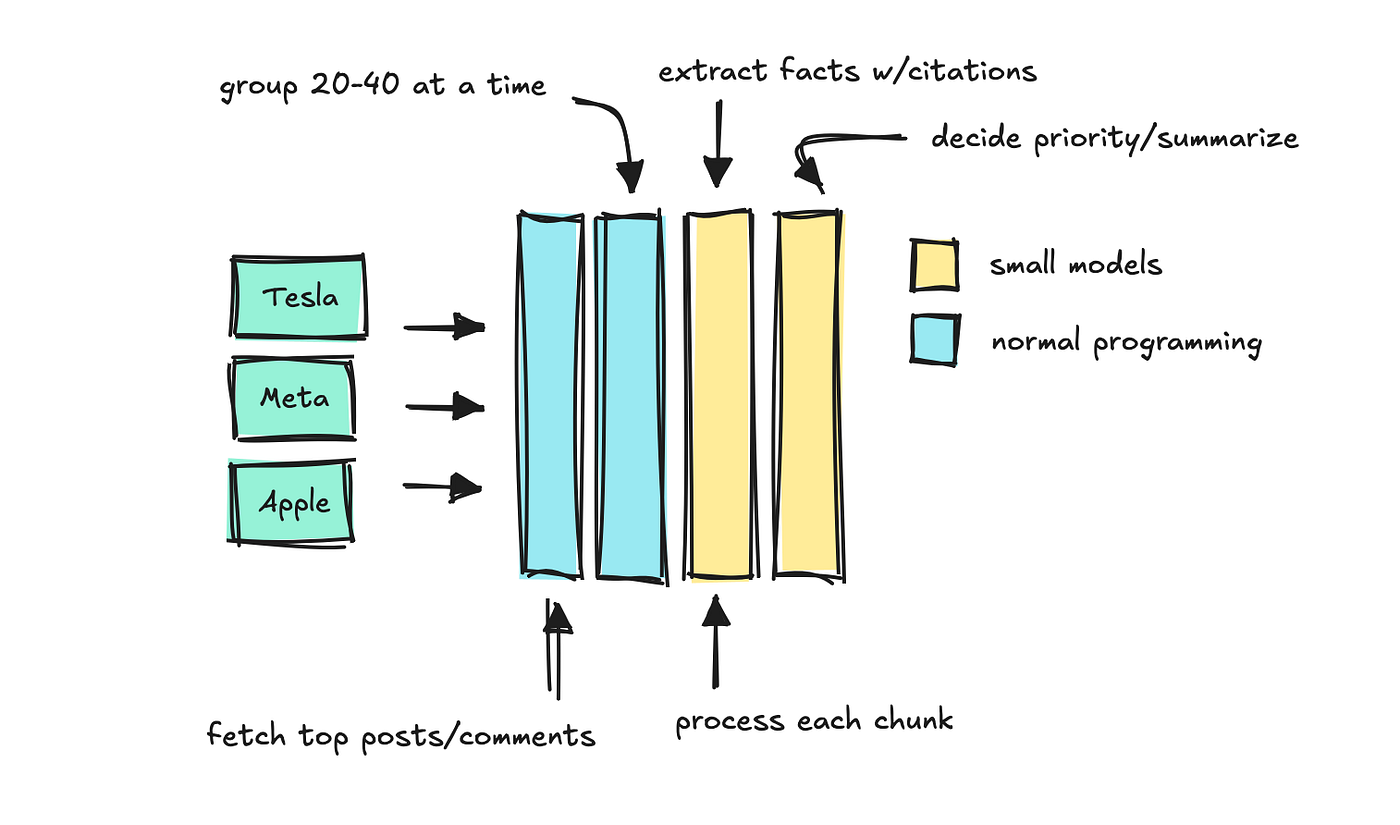
We apply a final LLM to summarize which details are most vital, preserving the supply citations intact.
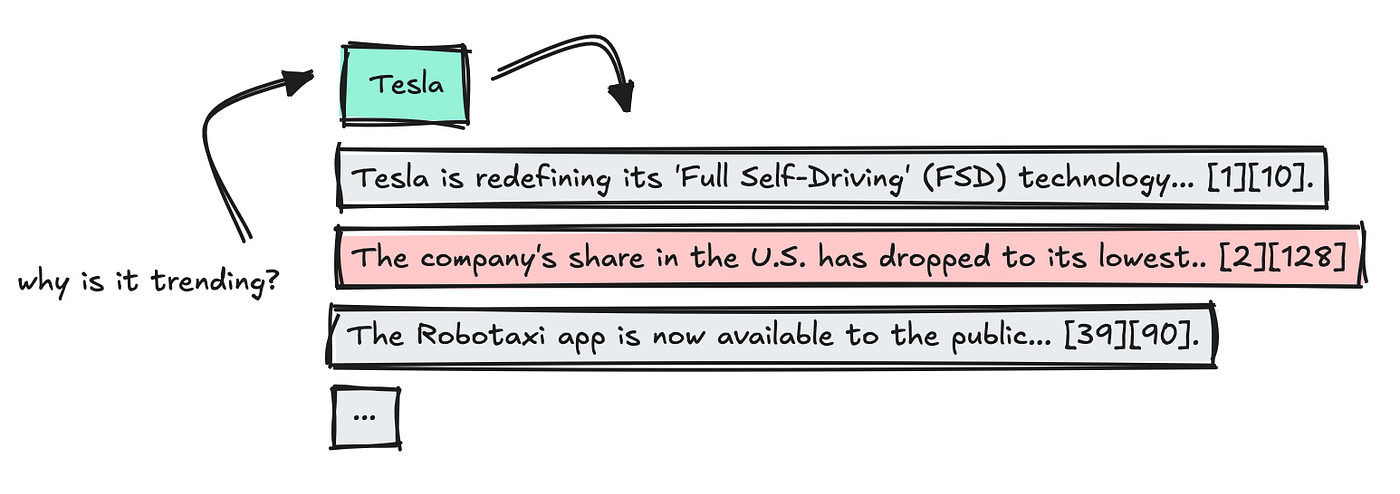
It is a sort of immediate chaining course of, and I constructed it to imitate LlamaIndex’s quotation engine.
The primary time the endpoint is named for a key phrase, it may take as much as half a minute to finish. However because the system caches the end result, any repeat request takes just some milliseconds.
So long as the fashions are sufficiently small, the price of working this on just a few hundred key phrases per day is minimal. Later, we will have the system run a number of key phrases in parallel.
You’ll be able to in all probability think about now that we will construct a system to fetch these key phrases and details to construct totally different studies with LLMs.
When to work with small vs bigger fashions
Earlier than transferring on, let’s simply point out that selecting the best mannequin dimension issues.
I believe that is on everybody’s thoughts proper now.
There are fairly superior fashions you should use for any workflow, however as we begin to apply an increasing number of LLMs to those purposes, the variety of calls per run provides up rapidly and this may get costly.
So, when you’ll be able to, use smaller fashions.
You noticed that I used smaller fashions to quote and group sources in chunks. Different duties which might be nice for small fashions embrace routing and parsing pure language into structured knowledge.
Should you discover that the mannequin is faltering, you’ll be able to break the duty down into smaller issues and use immediate chaining, first do one factor, then use that end result to do the following, and so forth.
You continue to wish to use bigger LLMs when it is advisable to discover patterns in very massive texts, or if you’re speaking with people.
On this workflow, the associated fee is minimal as a result of the information is cached, we use smaller fashions for many duties, and the one distinctive massive LLM calls are the ultimate ones.
How this agent works
Let’s undergo how the agent works underneath the hood. I constructed the agent to run inside Discord, however that’s not the main focus right here. We’ll concentrate on the agent structure.
I cut up the method into two elements: one setup, and one information. The primary course of asks the person to arrange their profile.
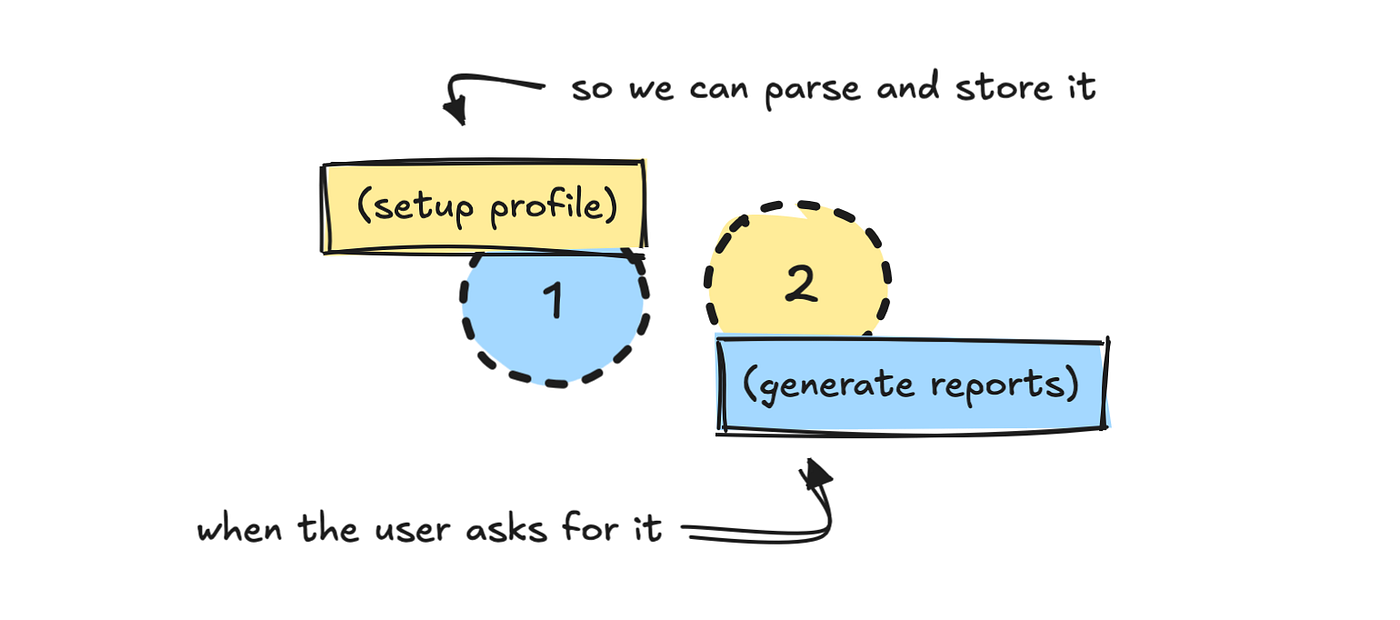
Since I already know easy methods to work with the information supply, I’ve constructed a reasonably intensive system immediate that helps the LLM translate these inputs into one thing we will fetch knowledge with later.
PROMPT_PROFILE_NOTES = """
You might be tasked with defining a person persona primarily based on the person's profile abstract.
Your job is to:
1. Choose a brief character description for the person.
2. Choose probably the most related classes (main and minor).
3. Select key phrases the person ought to monitor, strictly following the foundations under (max 6).
4. Determine on time interval (primarily based solely on what the person asks for).
5. Determine whether or not the person prefers concise or detailed summaries.
Step 1. Character
- Write a brief description of how we must always take into consideration the person.
- Examples:
- CMO for non-technical product → "non-technical, skip jargon, concentrate on product key phrases."
- CEO → "solely embrace extremely related key phrases, no technical overload, straight to the purpose."
- Developer → "technical, inquisitive about detailed developer dialog and technical phrases."
[...]
"""
I’ve additionally outlined a schema for the outputs I would like:
class ProfileNotesResponse(BaseModel):
character: str
major_categories: Checklist[str]
minor_categories: Checklist[str]
key phrases: Checklist[str]
time_period: str
concise_summaries: boolWith out having area data of the API and the way it works, it’s unlikely that an LLM would determine how to do that by itself.
You might attempt constructing a extra intensive system the place the LLM first tries to be taught the API or the methods it’s supposed to make use of, however that might make the workflow extra unpredictable and expensive.
For duties like this, I attempt to at all times use structured outputs in JSON format. That approach we will validate the end result, and if validation fails, we re-run it.
That is the best technique to work with LLMs in a system, particularly when there’s no human within the loop to test what the mannequin returns.
As soon as the LLM has translated the person profile into the properties we outlined within the schema, we retailer the profile someplace. I used MongoDB, however that’s optionally available.
Storing the character isn’t strictly required, however you do have to translate what the person says right into a kind that allows you to generate knowledge.
Producing the studies
Let’s take a look at what occurs within the second step when the person triggers the report.
When the person hits the /information command, with or and not using a time interval set, we first fetch the person profile knowledge we’ve saved.
This offers the system the context it must fetch related knowledge, utilizing each classes and key phrases tied to the profile. The default time interval is weekly.
From this, we get an inventory of prime and trending key phrases for the chosen time interval which may be attention-grabbing to the person.

With out this knowledge supply, constructing one thing like this is able to have been tough. The info must be ready upfront for the LLM to work with it correctly.
After fetching key phrases, it might make sense so as to add an LLM step that filters out key phrases irrelevant to the person. I didn’t do this right here.
The extra pointless data an LLM is handed, the tougher it turns into for it to concentrate on what actually issues. Your job is to make it possible for no matter you feed it’s related to the person’s precise query.
Subsequent, we use the endpoint ready earlier, which incorporates cached “details” for every key phrase. This offers us already vetted and sorted data for every one.
We run key phrase calls in parallel to hurry issues up, however the first individual to request a brand new key phrase nonetheless has to attend a bit longer.
As soon as the outcomes are in, we mix the information, take away duplicates, and parse the citations so every reality hyperlinks again to a particular supply by way of a key phrase quantity.
We then run the information by a prompt-chaining course of. The primary LLM finds 5 to 7 themes and ranks them by relevance, primarily based on the person profile. It additionally pulls out the important thing factors.
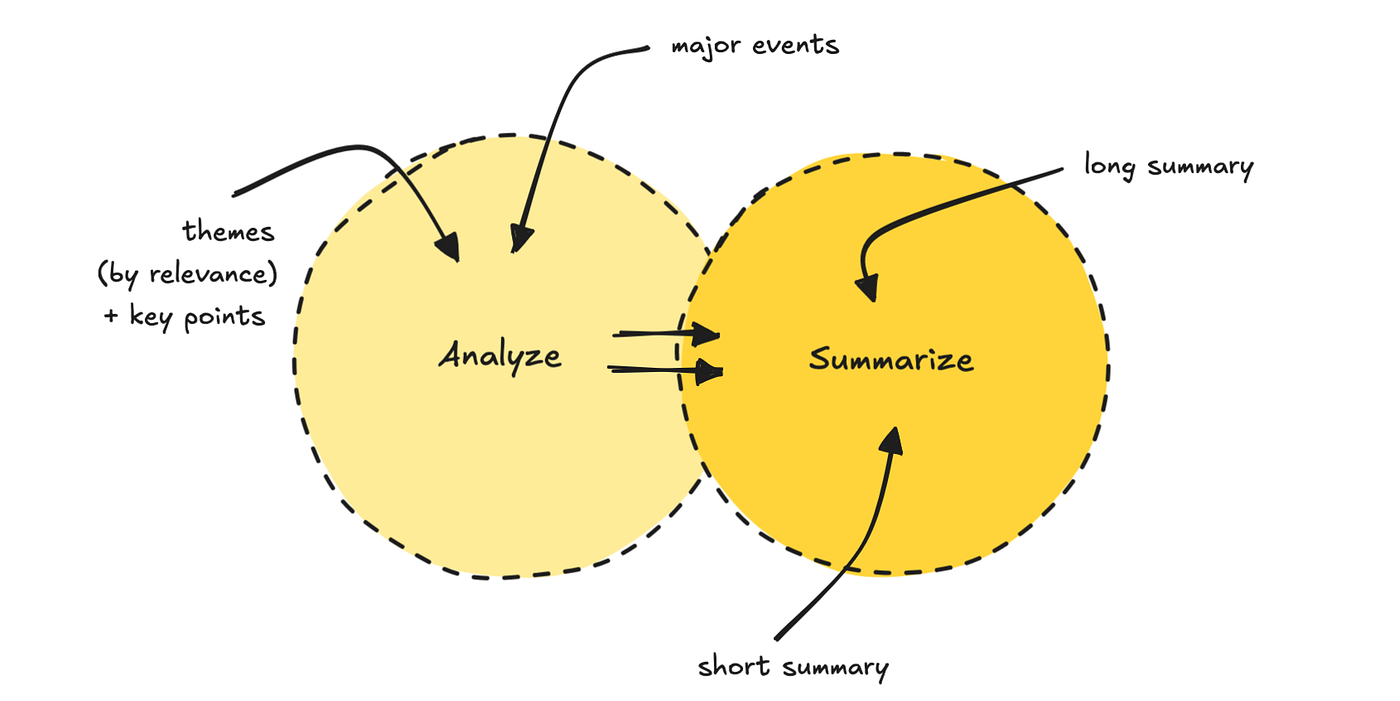
The second LLM move makes use of each the themes and authentic knowledge to generate two totally different abstract lengths, together with a title.
We will do that to ensure to scale back cognitive load on the mannequin.
This final step to construct the report takes probably the most time, since I selected to make use of a reasoning mannequin like GPT-5.
You might swap it for one thing sooner, however I discover superior fashions are higher at this final stuff.
The total course of takes a couple of minutes, relying on how a lot has already been cached that day.
Try the completed end result under.
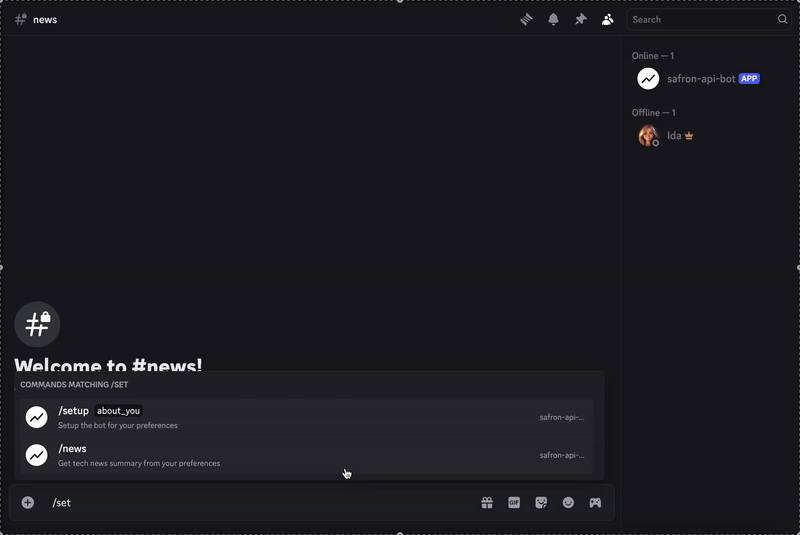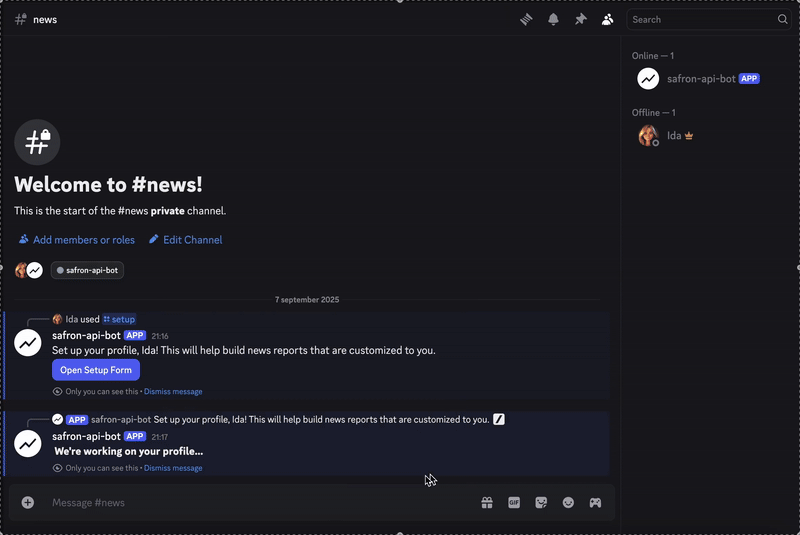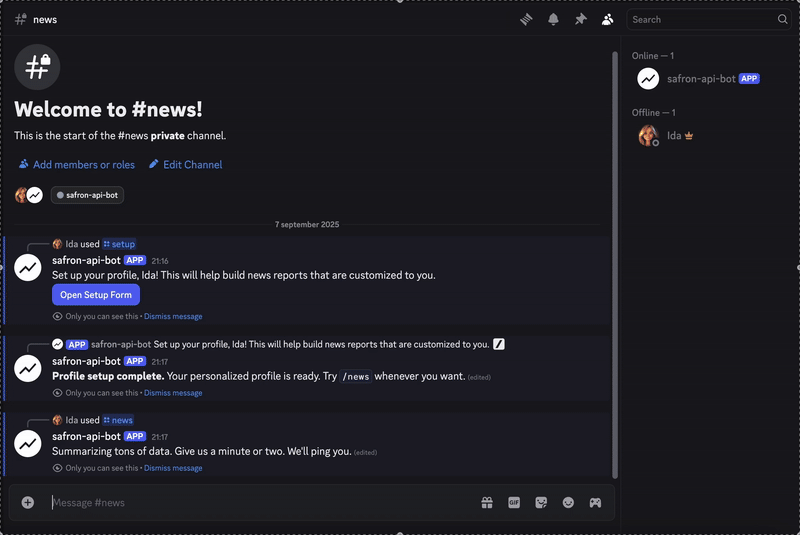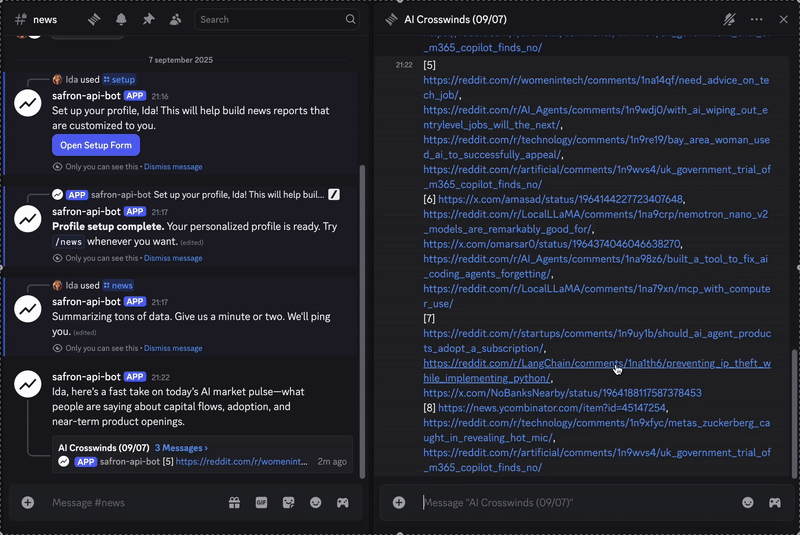
If you wish to take a look at the code and construct this bot your self, yow will discover it right here. Should you simply wish to generate a report, you’ll be able to be part of this channel.
I’ve some plans to enhance it, however I’m blissful to listen to suggestions if you happen to discover it helpful.
And if you need a problem, you’ll be able to rebuild it into one thing else, like a content material generator.
Notes on constructing brokers
Each agent you construct shall be totally different, so that is certainly not a blueprint for constructing with LLMs. However you’ll be able to see the extent of software program engineering this calls for.
LLMs, at the very least for now, don’t take away the necessity for good software program and knowledge engineers.
For this workflow, I’m principally utilizing LLMs to translate pure language into JSON after which transfer that by the system programmatically. It’s the best technique to management the agent course of, but in addition not what folks normally think about once they consider AI purposes.
There are conditions the place utilizing a extra free-moving agent is good, particularly when there’s a human within the loop.
Nonetheless, hopefully you discovered one thing, or received inspiration to construct one thing by yourself.
If you wish to comply with my writing, comply with me right here, my web site, Substack, or LinkedIn.
❤
[ad_2]


")

{kind=link}