
Picture offered by the authors – generated utilizing Gemini.
For many people, synthetic intelligence (AI) has develop into a part of on a regular basis life, and the speed at which we assign beforehand human roles to AI techniques exhibits no indicators of slowing down. AI techniques are the essential substances of many applied sciences — e.g., self-driving automobiles, good city planning, digital assistants — throughout a rising variety of domains. On the core of many of those applied sciences are autonomous brokers — techniques designed to behave on behalf of people and make choices with out direct supervision. As a way to act successfully in the true world, these brokers should be able to finishing up a variety of duties regardless of probably unpredictable environmental situations, which frequently requires some type of machine studying (ML) for attaining adaptive behaviour.
Reinforcement studying (RL) [6] stands out as a strong ML method for coaching brokers to realize optimum behaviour in stochastic environments. RL brokers be taught by interacting with their atmosphere: for each motion they take, they obtain context-specific rewards or penalties. Over time, they be taught behaviour that maximizes the anticipated rewards all through their runtime.
 Picture offered by the authors – generated utilizing Gemini.
Picture offered by the authors – generated utilizing Gemini.
RL brokers can grasp all kinds of advanced duties, from successful video video games to controlling cyber-physical techniques resembling self-driving automobiles, usually surpassing what knowledgeable people are able to. This optimum, environment friendly behaviour, nonetheless, if left solely unconstrained, might transform off-putting and even harmful to the people it impacts. This motivates the substantial analysis effort in secure RL, the place specialised methods are developed to make sure that RL brokers meet particular security necessities. These necessities are sometimes expressed in formal languages like linear temporal logic (LTL), which extends classical (true/false) logic with temporal operators, permitting us to specify situations like “one thing that should all the time maintain”, or “one thing that should finally happen”. By combining the adaptability of ML with the precision of logic, researchers have developed highly effective strategies for coaching brokers to behave each successfully and safely.
Nevertheless, security isn’t every part. Certainly, as RL-based brokers are more and more given roles that both exchange or carefully work together with people, a brand new problem arises: guaranteeing their conduct can be compliant with the social, authorized and moral norms that construction human society, which frequently transcend easy constraints guaranteeing security. For instance, a self-driving automobile may completely observe security constraints (e.g. avoiding collisions), but nonetheless undertake behaviors that, whereas technically secure, violate social norms, showing weird or impolite on the street, which could trigger different (human) drivers to react in unsafe methods.
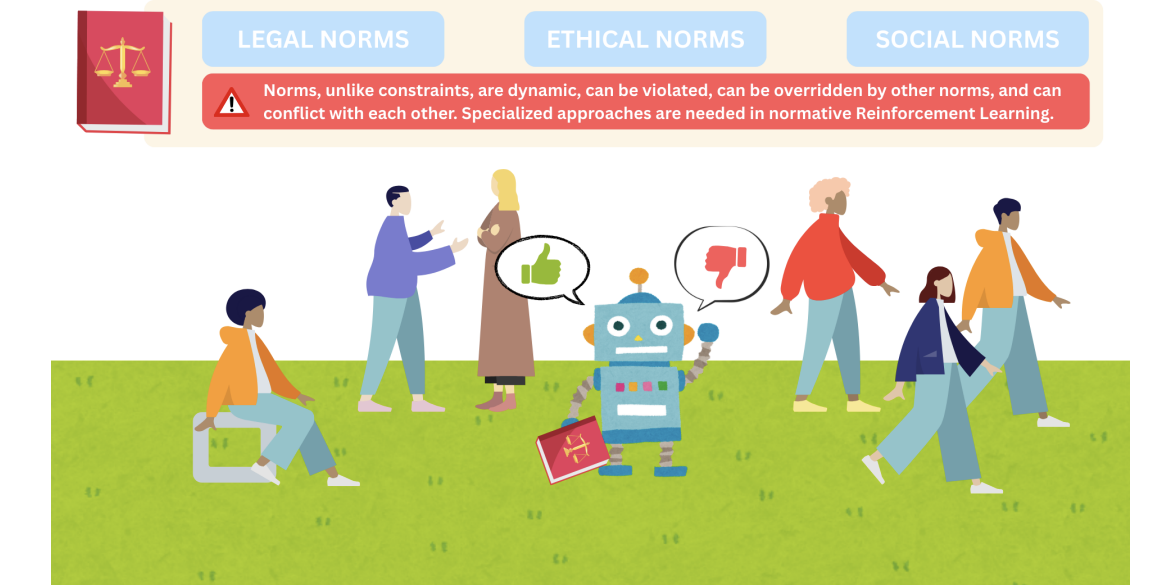
Norms are usually expressed as obligations (“you will need to do it”), permissions (“you’re permitted to do it”) and prohibitions (“you’re forbidden from doing it”), which aren’t statements that may be true or false, like classical logic formulation. As an alternative, they’re deontic ideas: they describe what is correct, incorrect, or permissible — preferrred or acceptable behaviour, as an alternative of what’s truly the case. This nuance introduces a number of tough dynamics to reasoning about norms, which many logics (resembling LTL) wrestle to deal with. Even every-day normative techniques like driving rules can function such issues; whereas some norms may be quite simple (e.g., by no means exceed 50 kph inside metropolis limits), others may be extra advanced, as in:
- At all times keep 10 meters between your automobile and the automobiles in entrance of and behind you.
- If there are lower than 10 meters between you and the automobile behind you, it’s best to decelerate to place extra space between your self and the automobile in entrance of you.
(2) is an instance of a contrary-to-duty obligation (CTD), an obligation you will need to observe particularly in a state of affairs the place one other major obligation (1) has already been violated to, e.g., compensate or cut back injury. Though studied extensively within the fields of normative reasoning and deontic logic, such norms may be problematic for a lot of primary secure RL strategies primarily based on implementing LTL constraints, as was mentioned in [4].
Nevertheless, there are approaches for secure RL that present extra potential. One notable instance is the Restraining Bolt method, launched by De Giacomo et al. [2]. Named after a tool used within the Star Wars universe to curb the conduct of droids, this methodology influences an agent’s actions to align with specified guidelines whereas nonetheless permitting it to pursue its targets. That’s, the restraining bolt modifies the conduct an RL agent learns in order that it additionally respects a set of specs. These specs, expressed in a variant of LTL (LTLf [3]), are every paired with its personal reward. The central thought is easy however highly effective: together with the rewards the agent receives whereas exploring the atmosphere, we add an extra reward at any time when its actions fulfill the corresponding specification, nudging it to behave in ways in which align with particular person security necessities. The task of particular rewards to particular person specs permits us to mannequin extra difficult dynamics like, e.g., CTD obligations, by assigning one reward for obeying the first obligation, and a distinct reward for obeying the CTD obligation.
Nonetheless, points with modeling norms persist; for instance, many (if not most) norms are conditional. Think about the duty stating “if pedestrians are current at a pedestrian crossing, THEN the close by automobiles should cease”. If an agent have been rewarded each time this rule was glad, it will additionally obtain rewards in conditions the place the norm just isn’t truly in pressure. It’s because, in logic, an implication holds additionally when the antecedent (“pedestrians are current”) is fake. In consequence, the agent is rewarded at any time when pedestrians aren’t round, and may be taught to extend its runtime as a way to accumulate these rewards for successfully doing nothing, as an alternative of effectively pursuing its supposed job (e.g., reaching a vacation spot). In [5] we confirmed that there are eventualities the place an agent will both ignore the norms, or be taught this “procrastination” conduct, regardless of which rewards we select. In consequence, we launched Normative Restraining Bolts (NRBs), a step ahead towards implementing norms in RL brokers. In contrast to the unique Restraining Bolt, which inspired compliance by offering extra rewards, the normative model as an alternative punishes norm violations. This design is impressed by the Andersonian view of deontic logic [1], which treats obligations as guidelines whose violation essentially triggers a sanction. Thus, the framework now not depends on reinforcing acceptable conduct, however as an alternative enforces norms by guaranteeing that violations carry tangible penalties. Whereas efficient for managing intricate normative dynamics like conditional obligations, contrary-to-duties, and exceptions to norms, NRBs depend on trial-and-error reward tuning to implement norm adherence, and due to this fact may be unwieldy, particularly when making an attempt to resolve conflicts between norms. Furthermore, they require retraining to accommodate norm updates, and don’t lend themselves to ensures that optimum insurance policies decrease norm violations.
Our contribution
Constructing on NRBs, we introduce Ordered Normative Restraining Bolts (ONRBs), a framework for guiding reinforcement studying brokers to adjust to social, authorized, and moral norms whereas addressing the constraints of NRBs. On this method, every norm is handled as an goal in a multi-objective reinforcement studying (MORL) downside. Reformulating the issue on this manner permits us to:
- Show that when norms don’t battle, an agent who learns optimum behaviour will decrease norm violations over time.
- Specific relationships between norms when it comes to a rating system describing which norm must be prioritized when a battle happens.
- Use MORL methods to algorithmically decide the mandatory magnitude of the punishments we assign such that it’s guarantied that as long as an agent learns optimum behaviour, norms will likely be violated as little as doable, prioritizing the norms with the very best rank.
- Accommodate modifications in our normative techniques by “deactivating” or “reactivating” particular norms.
We examined our framework in a grid-world atmosphere impressed by technique video games, the place an agent learns to gather assets and ship them to designated areas. This setup permits us to exhibit the framework’s means to deal with the advanced normative eventualities we famous above, together with direct prioritization of conflicting norms and norm updates. For example, the determine beneath
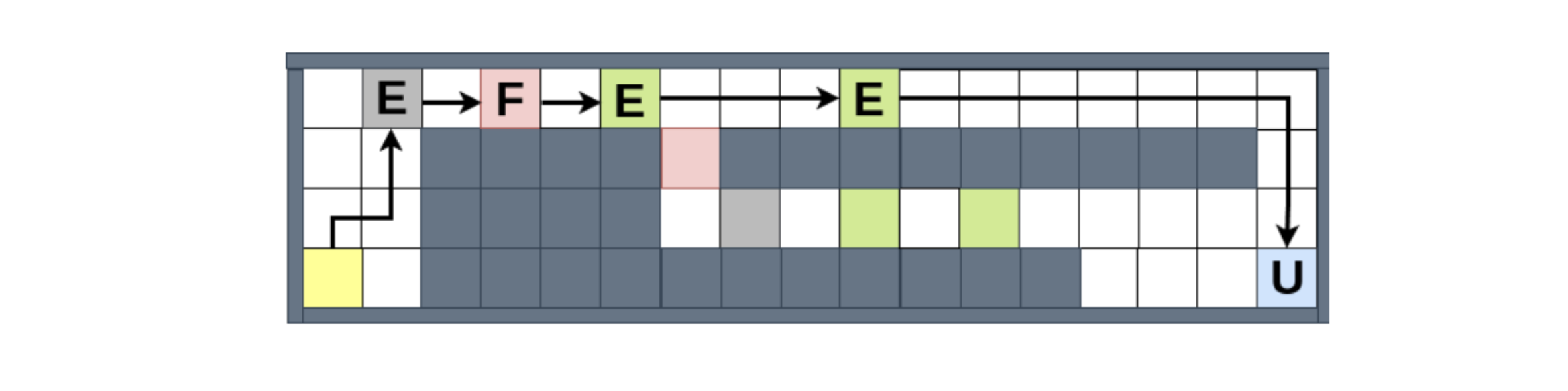
shows how the agent handles norm conflicts, when it’s each obligated to (1) keep away from the harmful (pink) areas, and (2) attain the market (blue) space by a sure deadline, supposing that the second norm takes precedence. We will see that it chooses to violate (1) as soon as, as a result of in any other case it will likely be caught originally of the map, unable to satisfy (2). Nonetheless, when given the chance to violate (1) as soon as extra, it chooses the compliant path, despite the fact that the violating path would enable it to gather extra assets, and due to this fact extra rewards from the atmosphere.
In abstract, by combining RL with logic, we are able to construct AI brokers that don’t simply work, they work proper.
This work received a distinguished paper award at IJCAI 2025. Learn the paper in full: Combining MORL with restraining bolts to be taught normative behaviour, Emery A. Neufeld, Agata Ciabattoni and Radu Florin Tulcan.
Acknowledgements
This analysis was funded by the Vienna Science and Expertise Fund (WWTF) venture ICT22-023 and the Austrian Science Fund (FWF) 10.55776/COE12 Cluster of Excellence Bilateral AI.
References
[1] Alan Ross Anderson. A discount of deontic logic to alethic modal logic. Thoughts, 67(265):100–103, 1958.
[2] Giuseppe De Giacomo, Luca Iocchi, Marco Favorito, and Fabio Patrizi. Foundations for restraining bolts: Reinforcement studying with LTLf/LDLf restraining specs. In Proceedings of the worldwide convention on automated planning and scheduling, quantity 29, pages 128–136, 2019.
[3] Giuseppe De Giacomo and Moshe Y Vardi. Linear temporal logic and linear dynamic logic on finite traces. In IJCAI, quantity 13, pages 854–860, 2013.
[4] Emery Neufeld, Ezio Bartocci, and Agata Ciabattoni. On normative reinforcement studying by way of secure reinforcement studying. In PRIMA 2022, 2022.
[5] Emery A Neufeld, Agata Ciabattoni, and Radu Florin Tulcan. Norm compliance in reinforcement studying brokers by way of restraining bolts. In Authorized Data and Info Techniques JURIX 2024, pages 119–130. IOS Press, 2024.
[6] Richard S. Sutton and Andrew G. Barto. Reinforcement studying – an introduction. Adaptive computation and machine studying. MIT Press, 1998.

Agata Ciabattoni
is a Professor at TU Wien.

Emery Neufeld
is a postdoctoral researcher at TU Wien.




{kind=link}