
[ad_1]
Retrieval is important in AI brokers. To do any job appropriately, the agent wants to have the ability to retrieve all the data that’s related to the duty from its reminiscence.
Context graphs are all the fad proper now, so I benchmarked them in opposition to the options.
This publish explains how every reminiscence methodology works, what the benchmark asks, what the information is, and what every methodology obtained proper and mistaken.
The agent failure case
Certainly one of our shoppers got here to us after their in-house agent stored dropping info. A sales-support agent which must know “which workplace handles our Acme account?” to do a job. It could not reply this.
The agent had every part it wanted for answering this in its reminiscence. Full dialog histories, vector databases on prime, the lot. Somebody had already famous that the Acme account is dealt with by Dana. Some place else, a PostgreSQL row famous that Dana works out of the Berlin workplace.
Each info had been sitting proper there however the agent didn’t retrieve them and put two and two collectively.
To appropriately retrieve and get the reply, the agent’s retrieval methodology needed to be part of two info that had been by no means stated in the identical breath, and nothing within the agent’s normal reminiscence setup did that by itself.
A context graph is constructed to repair these failures.
What similarity search cannot do
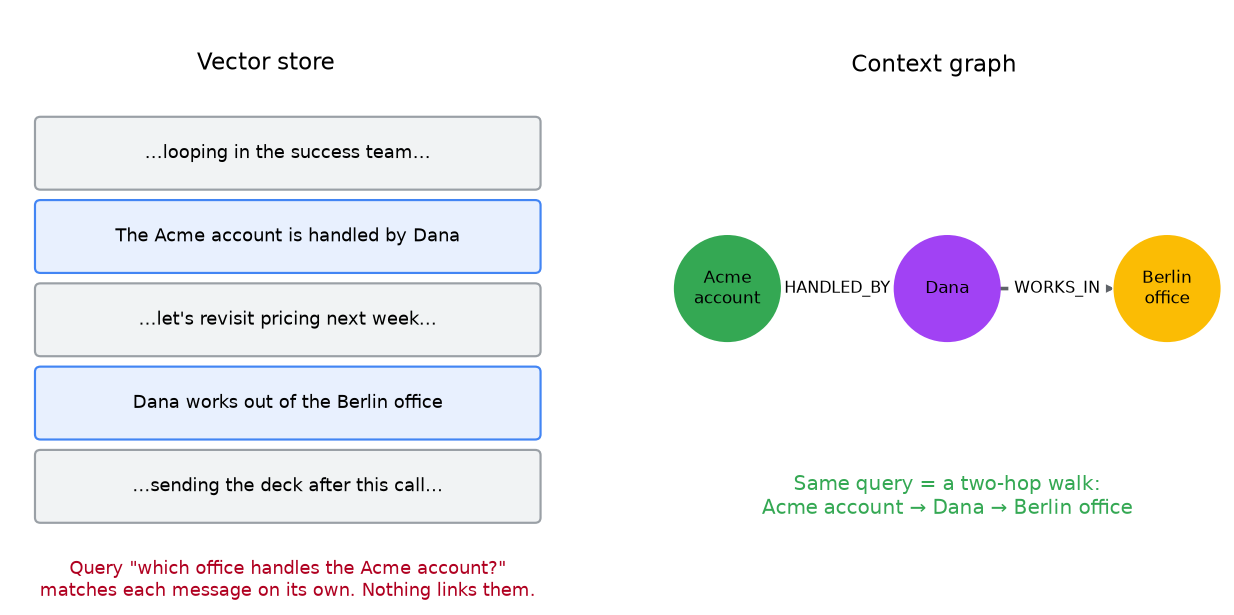
Listed below are two info an agent may ingest in its reminiscence, days aside:
The Acme account is dealt with by Dana.
Dana works out of the Berlin workplace.
Now the query is: “Which workplace handles the Acme account?”
No single message solutions it. It’s a must to chain two info that had been by no means stated collectively. That is referred to as a multi-hop query, as a result of the reply is 2 hops away: the Acme account, to Dana, to the Berlin workplace.
How every reminiscence methodology works
I examined 4 methods to present an agent reminiscence. Maintain the above instance in your head, I will use it to stroll by way of how every reminiscence methodology works. Once I get to the benchmark I will change to the information I really run (software program brokers coordinating on work).
Should you already learn about these retrieval strategies, skip to the benchmark.
1.Uncooked context
The only potential reminiscence the place you dump every part, together with the dialog histories and PostgreSQL dbs, within the reminiscence. The mannequin reads this textual content dump to reply the query.
Apparent points with this methodology that do not want a benchmark to grasp –
- Value. You resend the entire historical past on each single query, and that invoice grows with each message.
- Consideration. LLMs reliably learn the beginning and finish of an extended context and get hazy within the center.
2.Vector RAG
That is the usual manufacturing methodology at the moment. “RAG” is retrieval-augmented technology: as an alternative of sending every part, you attempt to retrieve solely the related bits from the reminiscence and ship these to the LLM.
- You are taking every message and run it by way of an embedding mannequin, which turns textual content into an inventory of numbers (a vector) that captures its that means.
- Comparable meanings land close to one another on this quantity area. “Who takes care of the Acme account” lands close to “the Acme account is dealt with by Dana”, as a result of the mannequin is aware of “takes care of” and “dealt with by” imply the identical factor. You retailer all these vectors.
- When a query is available in, you embed the query too, discover the handful of saved messages whose vectors are nearest, and ship solely these to the mannequin.
That is genuinely highly effective. It shrugs off wording. Ask who “takes care of” an account and it finds who it is “dealt with by.” And the associated fee is flat: you at all times ship the identical small handful of messages, regardless of how lengthy the historical past will get.
However discover what it does for the account query. It scores every message in opposition to your query by itself.
- “The Acme account is dealt with by Dana” seems to be related, it has “Acme account.”
- “Dana works out of the Berlin workplace” seems to be a lot much less related, as a result of your query by no means mentions Dana.
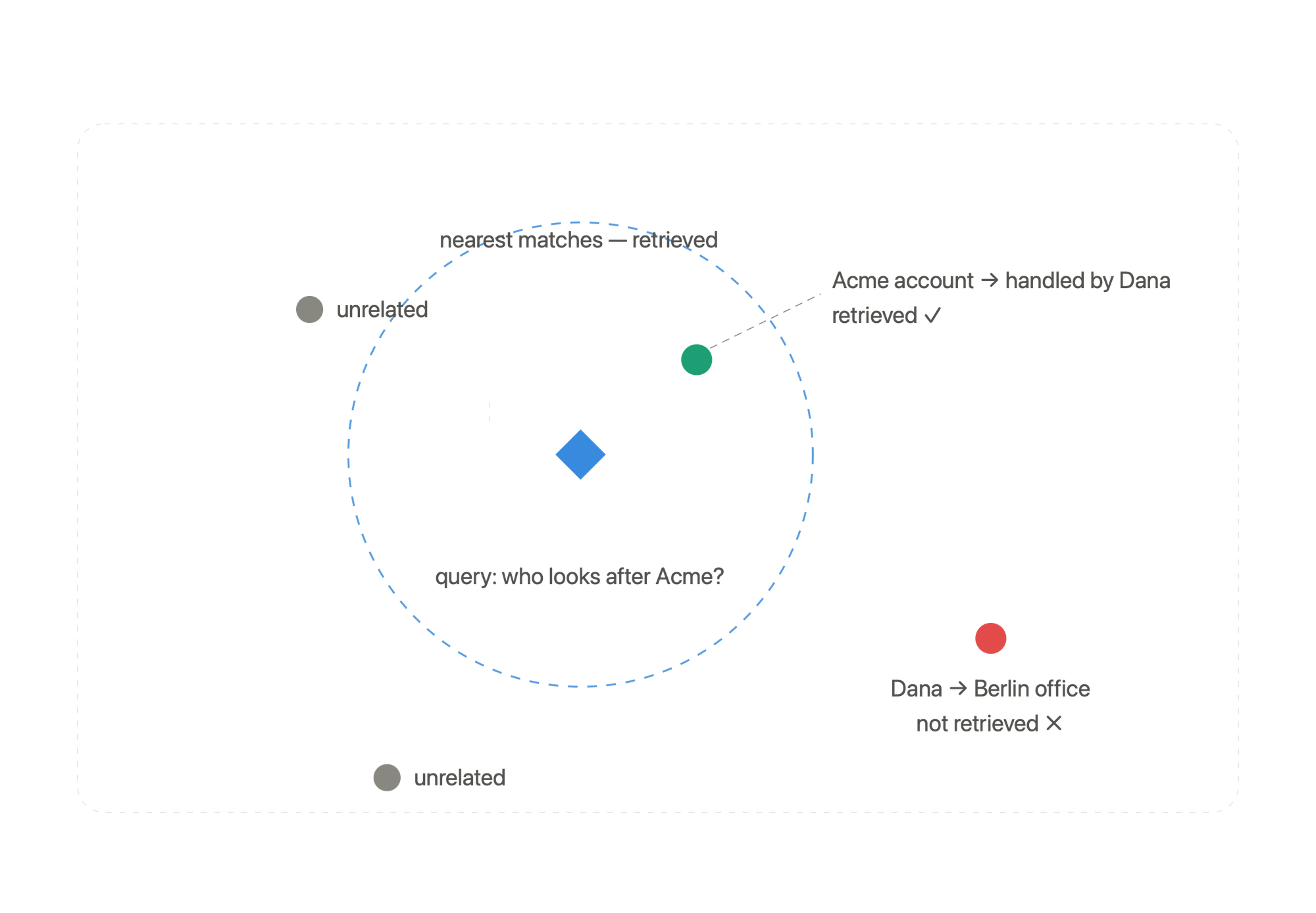
So the second reality, the one you really want for the workplace, usually would not get retrieved. Commonplace vector search ranks info one after the other. It has no option to say “fetch this reality, then observe it to the subsequent one.” And higher embeddings will not repair this.
3.Context graph
In a context graph, you cease storing the textual content instantly, and as an alternative retailer the info extracted from the textual content as a graph.
A graph is nodes related by edges. Every node turns into an entity, every edge turns into a relationship between entities. When the dialog histories and PostgresSQL dbs are ingested right into a context graph reminiscence, the 2 account info can be saved as follows:
(Acme account) --HANDLED_BY--> (Dana)
(Dana) --WORKS_IN--> (Berlin workplace)
Now the multi-hop query is a stroll on this graph. Begin on the Acme account, observe the HANDLED_BY edge to Dana, observe the WORKS_IN edge to the Berlin workplace. Two hops to get the precise reply. The graph does natively what vector search cannot: it follows one reality to the subsequent.
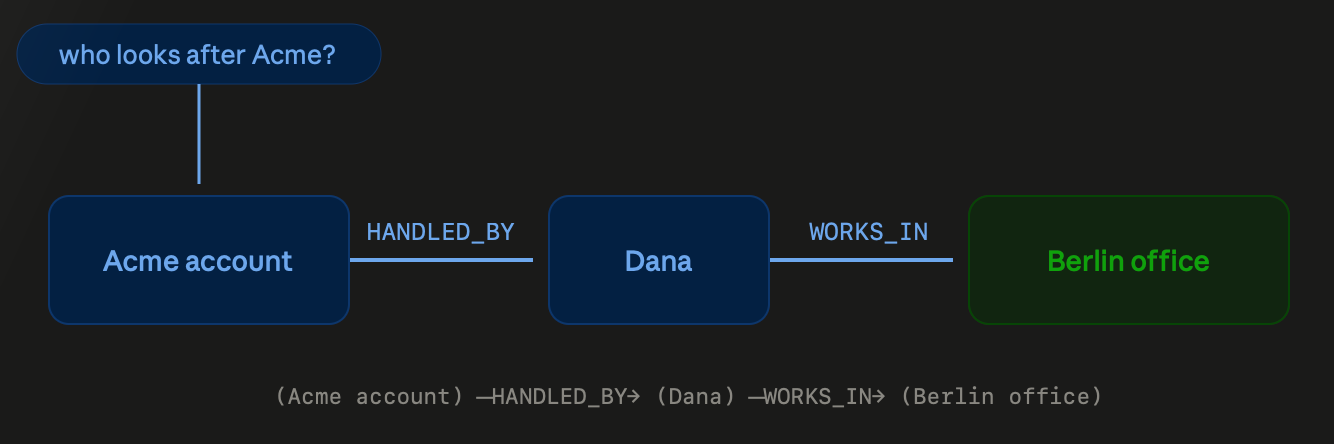
Two extra benefits right here –
- distance stops mattering, as a reality from message 3 and a reality from desk row 300 are each one hop from the node they describe, so outdated info are as simple to succeed in as new ones.
- It is tiny. It shops “Dana, works in, Berlin workplace”, not the paragraph that sentence got here in, so there’s virtually nothing to ship to the mannequin.
The troublesome, as you might have already sensed, is that to construct the graph you first have to show messy sentences into clear triples, and it is advisable do that effectively.
4.Hybrid
I added a hybrid methodology that made sense, the place I exploit the graph when it really works, and fall again to vectors when it would not.
Benchmark with artificial knowledge
Let’s depart our working instance behind right here.
I ran two benchmarks, one the place I created an artificial dataset myself, and one other the place I used the LoCoMo dataset.
I will begin with the artificial dataset. Every take a look at is on scripted conversations in one in all three Slack channels: software program, buyer account administration, advert hoc tasks. Just a few actual info get scattered by way of dozens of filler messages (“sounds good, syncing after standup”, “did the nightly construct cross?”). Then the benchmark asks questions and checks the reply in opposition to the recognized fact.
3 Slack channel varieties × 12 eventualities/seed × 5 seeds = 60 conversations. 6 checks on every dialog = 360 checks (60 per take a look at kind).
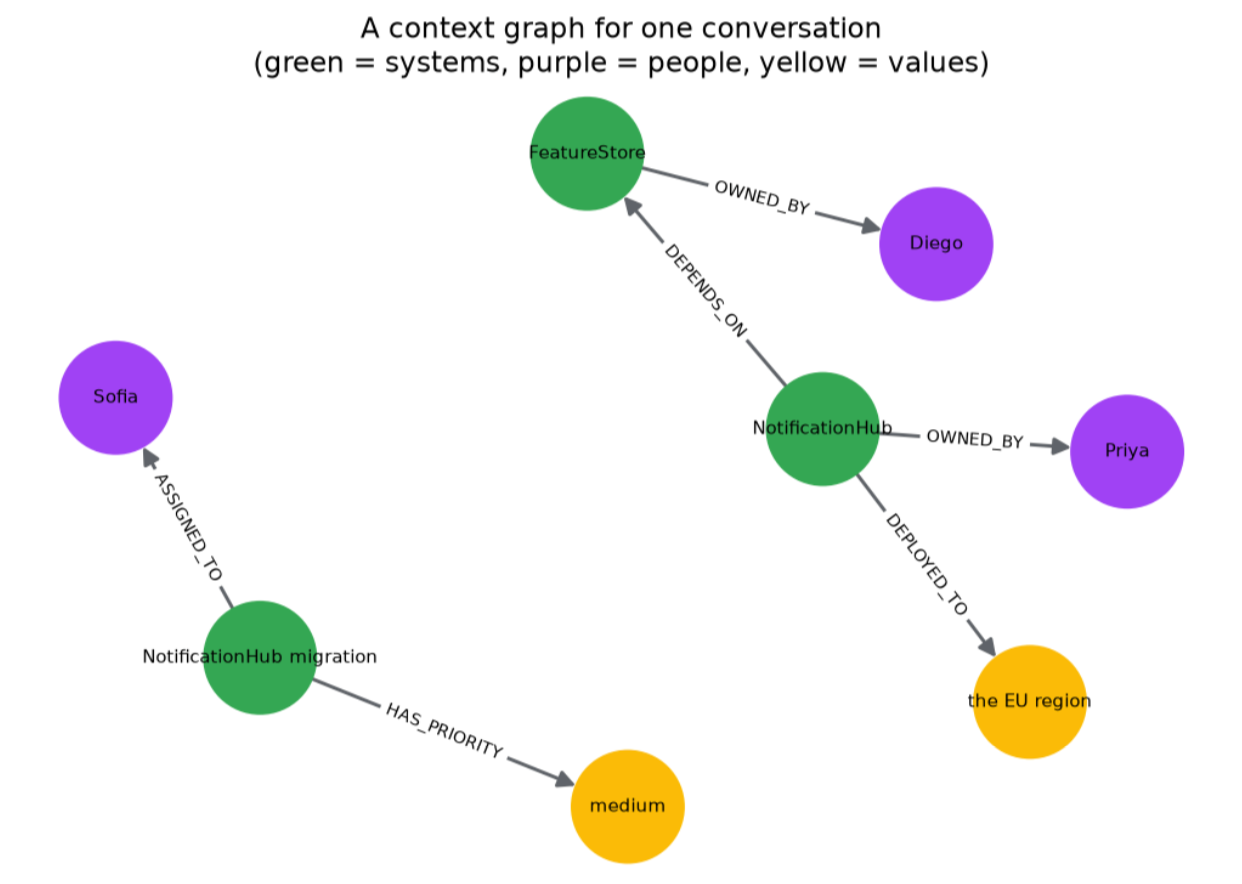
Instance dialog: infra_s0_0 (54 turns)
0 agent_b: Dash planning moved to Thursday.
1 agent_c: The demo went high quality, no blockers.
2 agent_b: FeatureStore is owned by Lena. <-- FACT
3 agent_a: Logs look clear on my finish.
4 agent_c: The demo went high quality, no blockers.
5 agent_b: Can somebody re-run the flaky take a look at?
6 agent_c: Grabbing espresso, again in 5.
7 agent_c: Heads up, CI is gradual at the moment.
8 agent_b: Lena is on the Belief crew. <-- FACT
9 agent_a: I will open a ticket for that later.
10 agent_b: Heads up, CI is gradual at the moment.
11 agent_c: Dash planning moved to Thursday.
12 agent_c: Cache hit fee seems to be wholesome.
13 agent_b: Logs look clear on my finish.
14 agent_a: Sounds good, I will sync after standup.
15 agent_a: No replace from the seller but.
16 agent_c: Sounds good, I will sync after standup.
17 agent_b: ReportingAPI is ready to excessive precedence. <-- FACT
18 agent_a: Heads up, CI is gradual at the moment.
19 agent_c: Grabbing espresso, again in 5.
20 agent_a: Thanks for the assessment earlier.
21 agent_a: The demo went high quality, no blockers.
22 agent_c: Bumping the reminiscence restrict on that pod.
23 agent_a: Grabbing espresso, again in 5.
24 agent_b: IngestWorker, which hundreds incoming occasions, will depend on ConfigService. <-- FACT
25 agent_b: Can somebody re-run the flaky take a look at?
26 agent_b: Let's circle again subsequent week.
27 agent_c: Can somebody re-run the flaky take a look at?
28 agent_c: Heads up, CI is gradual at the moment.
29 agent_c: Dash planning moved to Thursday.
30 agent_c: Let's circle again subsequent week.
31 agent_b: Grabbing espresso, again in 5.
32 agent_c: No replace from the seller but.
33 agent_b: ConfigService is owned by Sara. <-- FACT
34 agent_a: Let's circle again subsequent week.
35 agent_a: Dash planning moved to Thursday.
36 agent_a: Did the nightly construct cross?
37 agent_c: Logs look clear on my finish.
38 agent_b: Grabbing espresso, again in 5.
39 agent_a: The demo went high quality, no blockers.
40 agent_a: Did the nightly construct cross?
41 agent_a: No replace from the seller but.
42 agent_b: Replace: ReportingAPI is now medium precedence. <-- FACT (supersedes flip 17)
43 agent_a: Dash planning moved to Thursday.
44 agent_c: Fast query concerning the staging config.
45 agent_c: Logs look clear on my finish.
46 agent_b: Cache hit fee seems to be wholesome.
47 agent_c: I will open a ticket for that later.
48 agent_a: Heads up, CI is gradual at the moment.
49 agent_c: Can somebody re-run the flaky take a look at?
50 agent_b: Heads up, CI is gradual at the moment.
51 agent_a: Determination: ReportingAPI, which serves utilization reviews, will depend on FeatureStore. <-- FACT
52 agent_a: Sounds good, I will sync after standup.
53 agent_c: Logs look clear on my finish.All code, knowledge, outcomes are on this repository.
The six forms of checks on every dialog
I constructed six query varieties –
- Direct. A reality said not too long ago. “What does ReportingAPI depend upon?” Reply: FeatureStore. It is a sanity test every part ought to cross.
- Distant. A single reality said way back which is buried underneath distractors. “Which crew is Lena on?” Reply: Belief. Exams whether or not outdated info get misplaced within the noise.
- Be a part of (2 hops). Chain two info. “Who owns the part that ReportingAPI will depend on?” ReportingAPI will depend on FeatureStore, and FeatureStore is owned by Lena. Reply: Lena. The second reality by no means mentions ReportingAPI, so a retriever trying to find “ReportingAPI” will not discover it.
- Multi-hop (3 hops). Chain three info. “Which crew owns the part that ReportingAPI will depend on?”ReportingAPI, to FeatureStore, to Lena, to the Belief crew. Reply: Belief. Now a retriever has to land three particular turns without delay.
- Replace. A price modified, and the present one should win. “What precedence is ReportingAPI now?” It was excessive, then medium. Reply: medium. Exams whether or not stale info get cleared.
- Paraphrase. The entity is called by description, not by its id. “What does the analytics endpoint depend upon?” “The analytics endpoint” is ReportingAPI, however the dialog by no means says so explicitly. Reply: FeatureStore.
Outcomes on artificial knowledge
Accuracy by query kind:
| Technique | Direct | Distant | Be a part of | Multi-hop | Replace | Paraphrase | General |
|---|---|---|---|---|---|---|---|
| Uncooked dump | 100% | 100% | 33% | 33% | 100% | 0% | 61% |
| Vector RAG | 100% | 100% | 7% | 0% | 63% | 100% | 62% |
| Context graph | 100% | 100% | 100% | 100% | 100% | 0% | 83% |
| Hybrid | 100% | 100% | 100% | 100% | 100% | 100% | 100% |
Notice: The hybrid’s good 100% here’s a ceiling and never a manufacturing quantity. It assumes good reality extraction which is what this artificial benchmark fingers each methodology.
Direct and distant: everybody passes
| Query | Uncooked | Vector | Graph | Hybrid | Gold |
|---|---|---|---|---|---|
| Who owns FeatureStore? (direct) | Diego ✓ | Diego ✓ | Diego ✓ | Diego ✓ | Diego |
| Who owns NotificationHub? (distant) | Priya ✓ | Priya ✓ | Priya ✓ | Priya ✓ | Priya |
These are single info, said as soon as. An actual embedder finds them whether or not they had been stated one message in the past or fifty. Distance alone isn’t the issue.
Be a part of: solely the graph can chain info
| Query: who owns the part NotificationHub will depend on? | Reply | |
|---|---|---|
| Uncooked dump | Priya | ✗ |
| Vector RAG | Priya | ✗ |
| Context graph | Diego | ✓ |
| Hybrid | Diego | ✓ |
The entice right here is that NotificationHub’s personal proprietor is Priya, so a way that may’t do the second hop tends to reply Priya.
Have a look at the mistaken solutions. Uncooked dump and vector each stated Priya, and that is revealing. Priya owns NotificationHub. They retrieved the very fact about NotificationHub’s proprietor and stopped. They could not take the second hop, from NotificationHub to its dependency FeatureStore to that part’s proprietor.
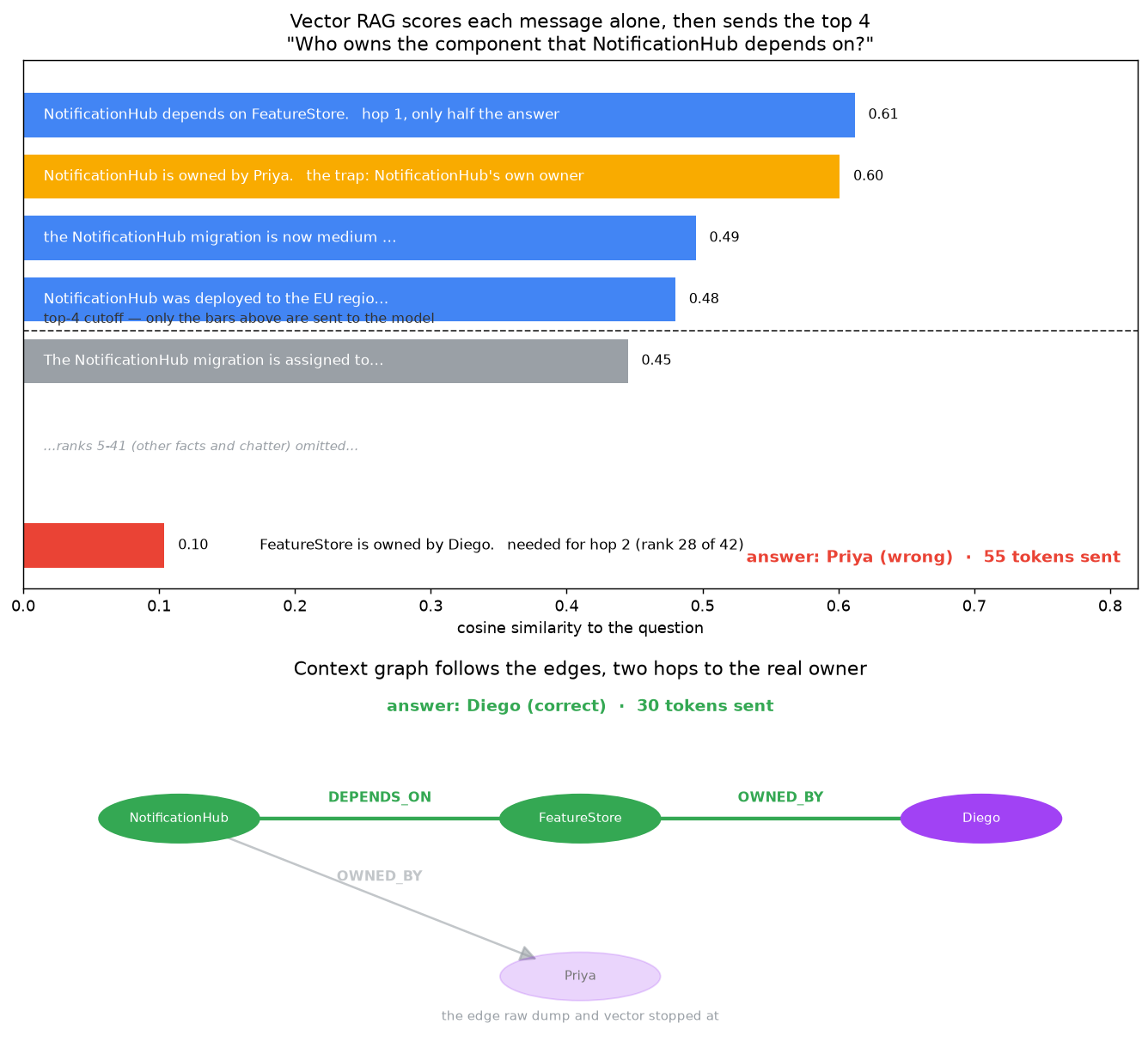
The wanted reality, “FeatureStore is owned by Diego”, would not point out NotificationHub, so vector RAG scores it low in opposition to a query about NotificationHub and by no means retrieves it.
The graph merely walked it: NotificationHub, DEPENDS_ON, FeatureStore, OWNED_BY, Diego.
Multi-hop: similar because the 2-hop be part of
| Query: which crew owns the part ReportingAPI will depend on? | Reply | |
|---|---|---|
| Uncooked dump | could not reply | ✗ |
| Vector RAG | could not reply | ✗ |
| Context graph | Belief | ✓ |
| Hybrid | Belief | ✓ |
Including a 3rd hop widens the hole. The reply wants three particular reality chains, ReportingAPI to FeatureStore, FeatureStore to Lena, Lena to Belief crew. Solely the primary reality names ReportingAPI explicitly. Vector RAG manages 0% right here, barely worse than its 7% on the two-hop be part of. The graph simply must take another step alongside the sides, and thus scores 100%.
Replace: vectors serve you stale info whereas graphs do not
| Query: what precedence is SearchIndexer now? | Reply | |
|---|---|---|
| Uncooked dump | important | ✓ |
| Vector RAG | low | ✗ |
| Context graph | important | ✓ |
| Hybrid | important | ✓ |
SearchIndexer was set to low precedence, then escalated to important. Vector RAG returned low, the stale worth. Each turns look virtually equivalent to the query “what precedence is it now”.
Vector search has no sense of time, so can randomly pull the older message and reply with a proven fact that’s now not true. It scores 63% throughout the checks, proper when retrieval occurs to floor the newer flip, mistaken when it grabs the stale one.
The graph will get it proper by design. When the brand new precedence arrived, it deleted the outdated edge earlier than including the brand new one, so the stale worth is solely gone.
Uncooked dump obtained it proper too, however by luck, not design. It at all times sees the latest messages and recency occurred to put it aside.
Paraphrase: blind spot of an ordinary context graph
| Query: who’s chargeable for the alerts system? | Reply | |
|---|---|---|
| Uncooked dump | the EU area | ✗ |
| Vector RAG | Priya | ✓ |
| Context graph | (nothing) | ✗ |
| Hybrid | Priya | ✓ |
The graph returned nothing in any respect. “The alerts system” is NotificationHub, however the graph shops a node actually named “NotificationHub”. It tried to match the phrases, discovered no node referred to as “alerts system”, and the stroll by no means began. The context graph scores zero p.c on paraphrase and that is its blind spot.
Vector search would not care what you name issues. “Alerts system” and “NotificationHub, which handles outbound notifications” are shut in that means, so it discovered the suitable message and browse off the proprietor.
Uncooked dump gave the funniest mistaken reply: the EU area. It grabbed a latest NotificationHub reality, i.e. one thing concerning the deployment area, and returned that.
Value and latency
Here is what every methodology spends to reply one query, measured in tokens with the GPT-4 tokenizer:
| Technique | Avg tokens per question | General accuracy |
|---|---|---|
| Uncooked dump | 477 | 60.0% |
| Vector RAG | 56 | 52.3% |
| Context graph | 15 | 80.0% |
| Hybrid | 26 | 92.3% |
Additionally, the uncooked dump’s value grows with the reminiscence dimension, whereas the others keep flat. I held the info fastened and padded the dialog with filler. At 800 turns the uncooked dump sends 13,623 tokens to reply one query. The graph sends 17, the identical because it did at flip one and solutions appropriately:
| Dialog size | Uncooked dump | Vector RAG | Context graph | Hybrid |
|---|---|---|---|---|
| 2 turns | 23 | 23 | 17 | 17 |
| 50 turns | 873 | 57 | 17 | 17 |
| 200 turns | 3,423 | 57 | 17 | 17 |
| 400 turns | 6,823 | 57 | 17 | 17 |
| 800 turns | 13,623 | 57 | 17 | 17 |
Retrieval velocity tells the identical story. These are in-memory occasions in milliseconds, median per question:
| Technique | Median retrieval latency (ms) |
|---|---|
| Uncooked dump | 0.038 |
| Vector RAG | 0.046 |
| Context graph | 0.005 |
| Hybrid | 0.004 |
The graph walks two edges whereas vector search embeds the query and scores it in opposition to each message, so traversal is a budget operation. The hybrid’s median is lowest as a result of the graph solutions most questions, and solely the paraphrase misses pay the embedding value.
What about recursive RAG?
Plain top-k is the naive baseline is vector RAG. Theoretically, you too can go for iterative / recursive retrieval. Take the take a look at we are saying earlier the place we requested “Who owns the part that ReportingAPI will depend on?”
- Spherical 1: top-k for the query → retrieves “ReportingAPI will depend on FeatureStore.”
- Spherical 2: now embed that retrieved chunk and discover its neighbours. That chunk accommodates FeatureStore, so “FeatureStore is owned by Diego” is now just like what you are looking with and it will get pulled in.
However that is inefficient. Why?
- It’s graph traversal over fuzzy edges. “Chunks that share an entity” is an implicit edge, and also you do BFS over it at question time. Iterative / recursive vector RAG will re-derive the graph on each question whereas the graph pays for this operation solely as soon as, as it’s precomputed at write time.
- Prime-4, then top-4 of every (16), then 64… most of it’s noise. You both blow up the token funds or prune aggressively and danger dropping the one chunk you wanted. The graph follows the related edges with way more precision.
- The bridge must be very clear for it to work. It really works on this instance as a result of “FeatureStore” is a tidy shared string. In actual dialogue the hyperlink is a pronoun, an implicit reference, or totally different wording (“the shop” / “it”), after which the growth drifts or misses.
- Naive growth drifts on general similarity. The variations that work effectively use an LLM to plan the hops (“first discover what ReportingAPI will depend on, then who owns that”), which suggests a number of LLM round-trips per query. You commerce the graph’s one low cost stroll for a reasoning loop.
If applied on the above benchmark, my guess is that recursive RAG closes a number of the 2-hop be part of hole, prices noticeably extra tokens, and nonetheless trails on the multi-hop case.
The hybrid methodology
The graph owns joins and updates, and vectors personal paraphrase, so one can simply use each.
The hybrid asks the graph first and takes the reply if the stroll succeeds. If the graph attracts a clean, which on this benchmark means a paraphrased query, it falls again to vector search.
That one rule retains each be part of and replace the graph obtained proper and recovers the paraphrases it dropped. It lands at 92.3% general, for 26 tokens a question.
The pure graph, for all its multi-hop energy, sits at 80% as a result of paraphrase drags it down. The lesson right here was to bolt your context graph reminiscence with strategies that may reply paraphrase questions.
Benchmark with actual knowledge
LoCoMo is a public dataset of ten very lengthy conversations, ~600 turns every, with 1,982 human-written checks.
| Property | Worth |
|---|---|
| Conversations | 10 |
| Messages whole | 5,882 |
| Messages per dialog (avg) | 588 |
| Exams (with proof) | 1,982 |
| Single-hop checks | 1,559 |
| Multi-hop checks | 423 |
In LoCoMo, every dialog is an extended relationship between two individuals, cut up into a number of chat classes (a number of chat classes in a dialog occurred days/weeks aside). Every chat session is an inventory of messages. For instance, conversation_0 had 19 chat classes with 419 whole messages. The dia_id encodes it: D1:3 = chat session 1, message 3.
Single-hop (one proof flip):
Q: “What was Melanie’s favourite ebook from her childhood?” Reply: “Charlotte’s Internet” Proof D6:10, Melanie: “I cherished studying ‘Charlotte’s Internet’ as a child. It was so cool seeing how friendship and compassion could make a distinction.”
Multi-hop (a number of proof turns in a number of chat classes):
Q: “What do Melanie’s youngsters like?” Reply: dinosaurs, nature Proof D6:6, Melanie: “They had been stoked for the dinosaur exhibit! They love studying about animals…” Proof D4:8, Melanie: “It was an superior time! They love exploring nature, they usually additionally roasted marshmallows across the campfire…”
The nice factor was the dataset gave proof labels within the take a look at solutions, which let me take a look at this with no LLM in any respect.
Outcomes on actual knowledge
Every thing up to now fingers every methodology good, pre-extracted info. That isolates retrieval, which is what I needed to measure. However in manufacturing, an LLM has to learn every reminiscence ingestion request and pull out the triples.
The graph wants triples, so Claude Haiku reads the dialogue in batches and extracts them in a context graph.
def batch_extract(turns, batch=12):
triples = []
for chunk in batches(turns, batch):
textual content = "n".be part of(f"[{t.speaker}] {t.textual content}" for t in chunk)
# "Extract relationships as JSON: [{subject, predicate, object}]"
triples += parse_json(claude(EXTRACT_PROMPT + textual content))
return triples # ~1 triple per activate LoCoMo
Then I used the context graph to determine which messages to learn (take the highest triples, observe their entities one hop to the related info, map these info again to the messages they got here from), and hand the mannequin these messages:
prime = argsort(-(triple_vectors @ embed(query)))[:k] # prime triples
seed = {s for s,p,o in prime} | {o for s,p,o in prime}
hood = rank_by_similarity(t for t in triples if t.topic in seed or t.object in seed)[:k]
turns = {provenance[t] for t in prime + hood} # again to supply messages
ctx = info(prime + hood) + "n" + "n".be part of(turn_text[i] for i in sorted(turns))
graph_answer = claude(f"Reply utilizing solely:n{ctx}nnQ: {query}")Vector RAG embeds each uncooked flip and, per query, sends the top-k turns to Haiku to reply:
qv = embed(query)
prime = argsort(-(turn_vectors @ qv))[:k] # top-k turns by cosine
ctx = "n".be part of(turn_text[i] for i in prime)
vector_answer = claude(f"Reply utilizing solely:n{ctx}nnQ: {query}")A separate Claude Haiku name judges every reply in opposition to the reality. Here is how they landed:
| Query kind | Vector RAG | Context graph |
|---|---|---|
| Single-hop (20 Q) | 20.0% | 45.0% |
| Multi-hop (6 Q) | 16.7% | 33.3% |
| All (26 Q) | 19.2% | 42.3% |
| Query Examples | Context graph | Vector RAG | Reality |
|---|---|---|---|
| When did Gina get her tattoo? | “Just a few years in the past” ✓ | “Unknown” ✗ | Just a few years in the past |
| For the way lengthy has Nate had his turtles? | “3 years” ✓ | “Unknown” ✗ | 3 years |
| What objects did John point out having as a toddler? | “movie digital camera and slightly doll” ✓ | “Unknown” ✗ | a doll, a movie digital camera |
| What do Jon and Gina have in frequent? | “misplaced their jobs, began a enterprise” ✓ | “ardour for dancing” ✗ | misplaced jobs, began personal enterprise |
In most of those checks, the reply lived in a flip that by no means made vector’s top-25, however the context graph triples for it sat comparatively nearer to the query within the graph.
Fixing the graph’s blind spots
My level was to indicate the benefits that context graphs carry when utilized in AI brokers. That is under no circumstances a manufacturing grade implementation of context graphs, which tends to be much more technically rigorous.
What would transfer the context graph rating above 42.3%?
There are lots of optimizations that manufacturing groups use to enhance how they make use of context graphs –
1.Higher search
My context graph solutions in two distinct steps:
- Entity linking. Flip the query’s point out (“the analytics endpoint”) right into a beginning node (“ReportingAPI”).
- Traversal. From that node, observe edges (DEPENDS_ON, then OWNED_BY). That is deterministic pointer-chasing with no mannequin within the loop, additionally the explanation why the graph is affordable (15–30 tokens, microseconds).
The paraphrase failures occur totally in step 1, earlier than any traversal occurs. In my benchmark the resolver (ContextGraphMemory._resolve) matches the point out to a node by lexical token overlap:
“the analytics endpoint” vs node “ReportingAPI” -> shared tokens: 0 -> no match
The graph is not dangerous on the query; it simply by no means will get to ask it.
However manufacturing programs make step 1 semantic, the place you embed the node labels (or ask an LLM) and match “analytics endpoint” → “ReportingAPI, which serves utilization reviews” by that means.
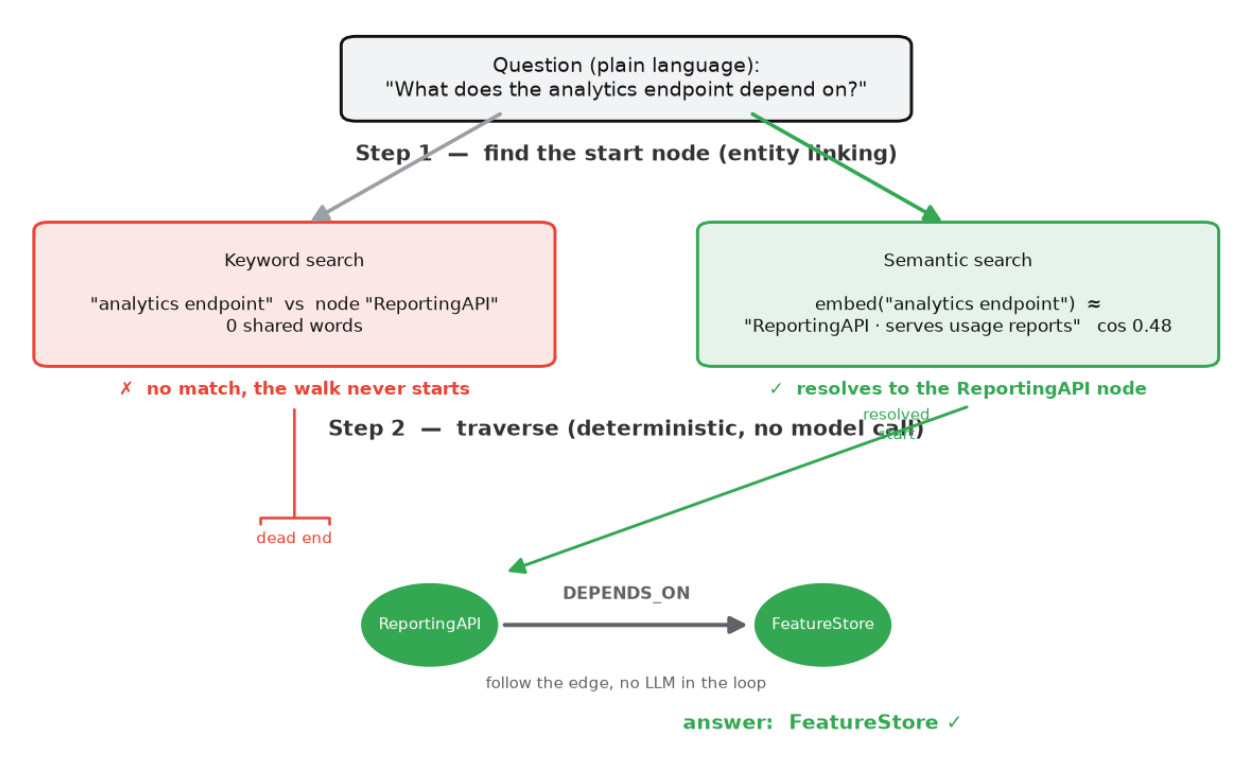
As a substitute of key phrase search, we are able to use semantic search on the context graph to utterly remedy for the paraphrase checks and in addition do higher on the LoCoMo dataset.
2.Higher extraction
The graph is barely ever pretty much as good because the triples you pull out of the textual content.
- Extract in multiple cross. One learn of an extended message leaves info on the ground. Run it once more, or ask the mannequin what it missed the primary time. The second cross is affordable subsequent to the price of by no means having the very fact.
- Give the extractor a schema. Hand it the relation varieties you care about, OWNED_BY, REPORTS_TO, DEPENDS_ON, so it fills fastened fields as an alternative of inventing a predicate each time. Inconsistent predicates are precisely why updates and joins broke for me: “has precedence”, “is now”, and “precedence set to” are three keys for one relationship, and the graph cannot line them up. A schema pins them down.
- Maintain the supply textual content subsequent to each reality. For instance, hand the mannequin the unique knowledge embedded within the graph node as an attribute, not simply the terse triple.
- Seize what triples normally throw away. Checklist objects as separate edges, timestamps on edges so “when did she go?” has a date to search out, and pronouns resolved to names at write time, so “she” turns into “Melanie” earlier than it reaches a node.
All of this prices mannequin calls at ingestion. That could be a low cost commerce the place you pay as soon as per message, up entrance, so each later question stays low cost and proper. For an agent that solutions many questions over an extended historical past, that commerce normally pays for itself.
3.Higher mannequin
A stronger mannequin helps in two locations, and they aren’t equally essential.
At extraction, which is the place it issues most. A extra cautious mannequin reads a rambling message and pulls out extra of the info, with cleaner entities and fewer innovations. Extraction caps the entire rating, so the mannequin you extract with issues greater than the one you reply with. Spend your funds upstream.
At answering, for the questions that are not lookups. “Would Caroline pursue writing?” is not saved anyplace. The mannequin has to purpose from what was. A stronger reader turns “listed below are the info” into the suitable inference extra usually, and that’s most of what is left as soon as retrieval is solved.
The place to make use of context graphs
Construct a context graph when your brokers run lengthy, selections made early must survive many turns, and questions chain info collectively. That is most multi-agent work.
Enterprises and startups use our agentic harnesses and context graphs to automate varied processes, together with ones with –
- Excessive crew dimension. You probably have 50 individuals working a workflow manually. The headcount is excessive solely as a result of the choice logic is just too complicated to automate with conventional AI instruments.
- Exception-heavy selections. Take into consideration procurement, insurance coverage claims, deal desks, compliance. In these jobs, the reply is at all times “it relies upon.”
- Cross-functional roles. RevOps, FinOps, DevOps, Safety Ops. These roles emerge exactly as a result of no single system of document owns the cross-functional workflow. Your organization creates a task to hold the context.
Procurement, finance, claims, deal desk, underwriting, escalation administration are few examples.
Learn extra right here.
You’ll be able to skip it when conversations are brief, or when questions are fuzzy and open-ended, the sort the place you need semantic recall greater than a precise stroll. Notice that graph provides an extraction value you will have incur and a vocabulary downside you will want to repair.
The code, knowledge, and each desk listed below are reproducible from the repository.
[ad_2]




{kind=link}