
Most AI brokers at this time have a elementary amnesia downside. Deploy one to browse the online, resolve GitHub points, or navigate a purchasing platform, and it approaches each single job as if it has by no means seen something prefer it earlier than. Irrespective of what number of instances it has came upon the identical kind of downside, it repeats the identical errors. Helpful classes evaporate the second a job ends.
A crew of researchers from Google Cloud AI, the College of Illinois Urbana-Champaign and Yale College introduces ReasoningBank, a reminiscence framework that doesn’t simply document what an agent did — it distills why one thing labored or failed into reusable, generalizable reasoning methods.
The Drawback with Current Agent Reminiscence
To grasp why ReasoningBank is vital, you have to perceive what current agent reminiscence really does. Two standard approaches are trajectory reminiscence (utilized in a system referred to as Synapse) and workflow reminiscence (utilized in Agent Workflow Reminiscence, or AWM). Trajectory reminiscence shops uncooked motion logs — each click on, scroll, and typed question an agent executed. Workflow reminiscence goes a step additional and extracts reusable step-by-step procedures from profitable runs solely.
Each have crucial blind spots. Uncooked trajectories are noisy and too lengthy to be immediately helpful for brand spanking new duties. Workflow reminiscence solely mines profitable makes an attempt, which suggests the wealthy studying sign buried in each failure — and brokers fail quite a bit — will get fully discarded.
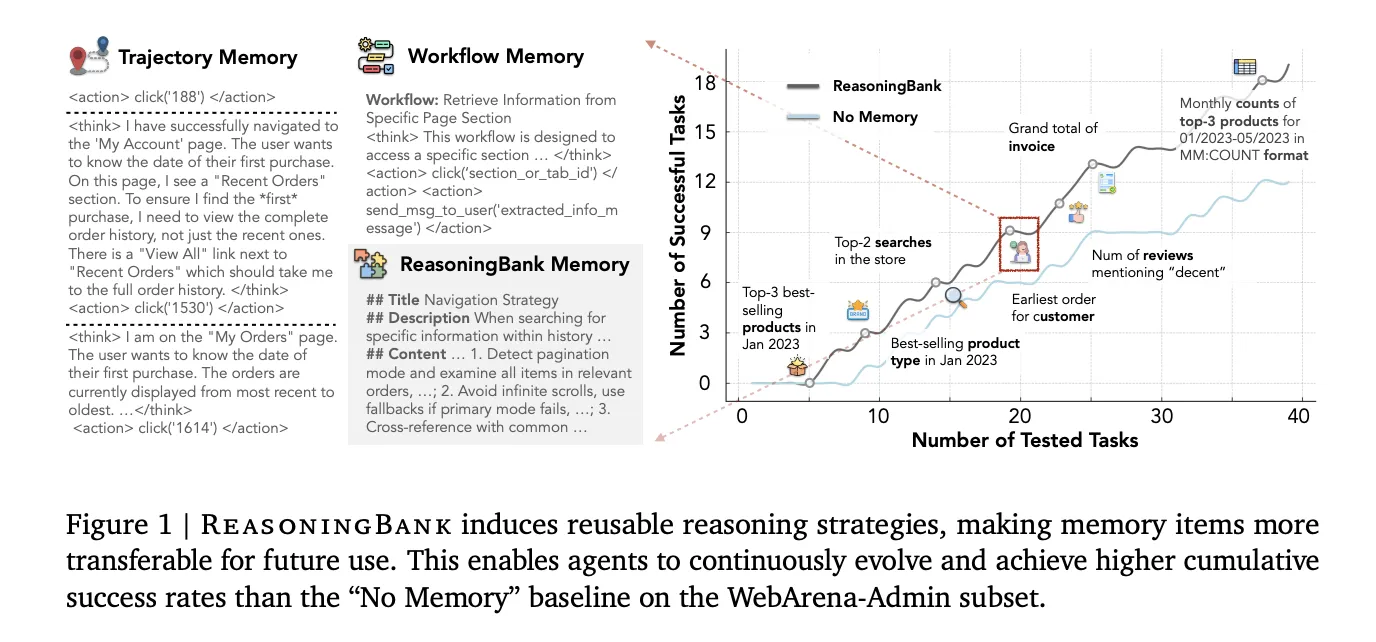
How ReasoningBank Works
ReasoningBank operates as a closed-loop reminiscence course of with three phases that run round each accomplished job: reminiscence retrieval, reminiscence extraction, and reminiscence consolidation.
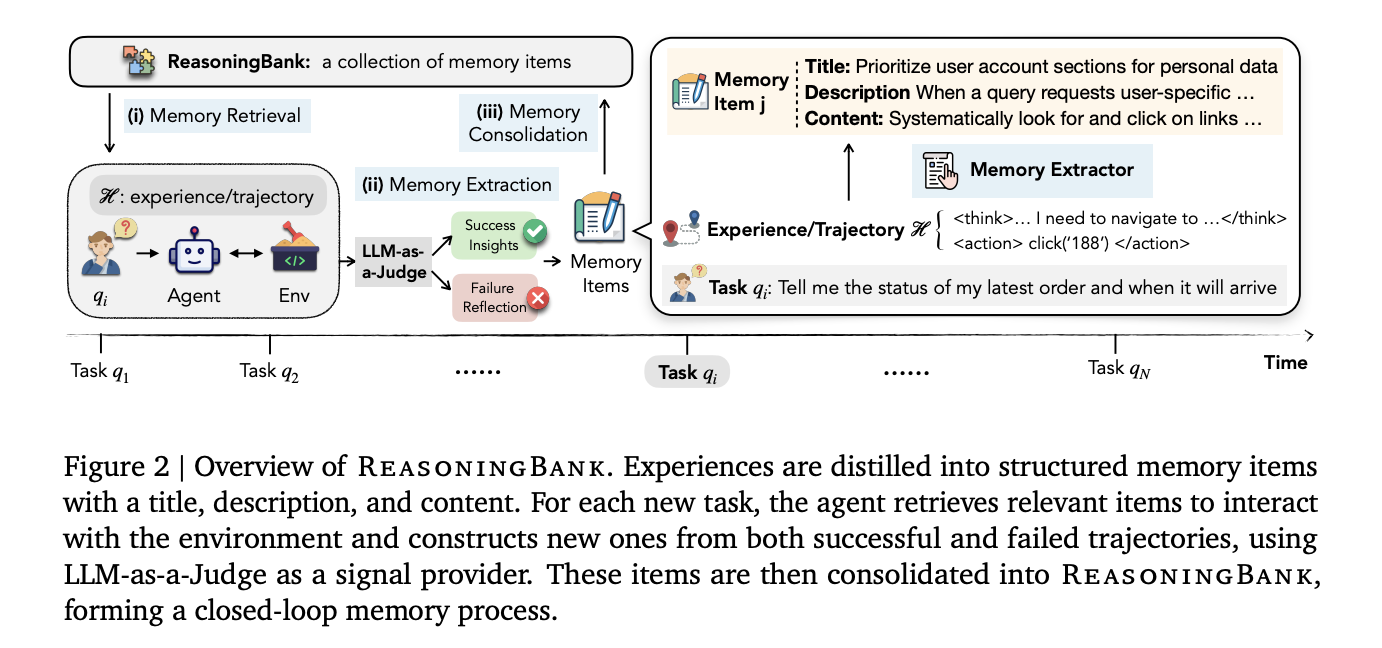
Earlier than an agent begins a brand new job, it queries ReasoningBank utilizing embedding-based similarity search to retrieve the top-ok most related reminiscence gadgets. These gadgets get injected immediately into the agent’s system immediate as further context. Importantly, the default is ok=1, a single retrieved reminiscence merchandise per job. Ablation experiments present that retrieving extra recollections really hurts efficiency: success price drops from 49.7% at ok=1 to 44.4% at ok=4. The standard and relevance of retrieved reminiscence matter excess of amount.
As soon as the duty is completed, a Reminiscence Extractor — powered by the identical spine LLM because the agent — analyzes the trajectory and distills it into structured reminiscence gadgets. Every merchandise has three parts: a title (a concise technique identify), a description (a one-sentence abstract), and content material (1–3 sentences of distilled reasoning steps or operational insights). Crucially, the extractor treats profitable and failed trajectories in a different way: successes contribute validated methods, whereas failures provide counterfactual pitfalls and preventative classes.
To resolve whether or not a trajectory was profitable or not — with out entry to ground-truth labels at check time — the system makes use of an LLM-as-a-Choose, which outputs a binary “Success” or “Failure” verdict given the person question, the trajectory, and the ultimate web page state. The decide doesn’t must be good; ablation experiments present ReasoningBank stays strong even when decide accuracy drops to round 70%.
New reminiscence gadgets are then appended on to the ReasoningBank retailer, maintained as JSON with pre-computed embeddings for quick cosine similarity search, finishing the loop.
MaTTS: Pairing Reminiscence with Take a look at-Time Scaling
The analysis crew goes additional and introduces memory-aware test-time scaling (MaTTS), which hyperlinks ReasoningBank with test-time compute scaling — a method that has already confirmed highly effective in math reasoning and coding duties.
The perception is straightforward however vital: scaling at check time generates a number of trajectories for a similar job. As an alternative of simply selecting the perfect reply and discarding the remainder, MaTTS makes use of the total set of trajectories as wealthy contrastive indicators for reminiscence extraction.
MaTTS is available in two methods. Parallel scaling generates ok impartial trajectories for a similar question, then makes use of self-contrast — evaluating what went proper and unsuitable throughout all trajectories — to extract higher-quality, extra dependable reminiscence gadgets. Sequential scaling iteratively refines a single trajectory utilizing self-refinement, capturing intermediate corrections and insights as reminiscence indicators.
The result’s a optimistic suggestions loop: higher reminiscence guides the agent towards extra promising rollouts, and richer rollouts forge even stronger reminiscence. The paper notes that at ok=5, parallel scaling (55.1% SR) edges out sequential scaling (54.5% SR) on WebArena-Purchasing — sequential positive aspects saturate rapidly as soon as the mannequin reaches a decisive success or failure, whereas parallel scaling retains offering numerous rollouts that the agent can distinction and study from.
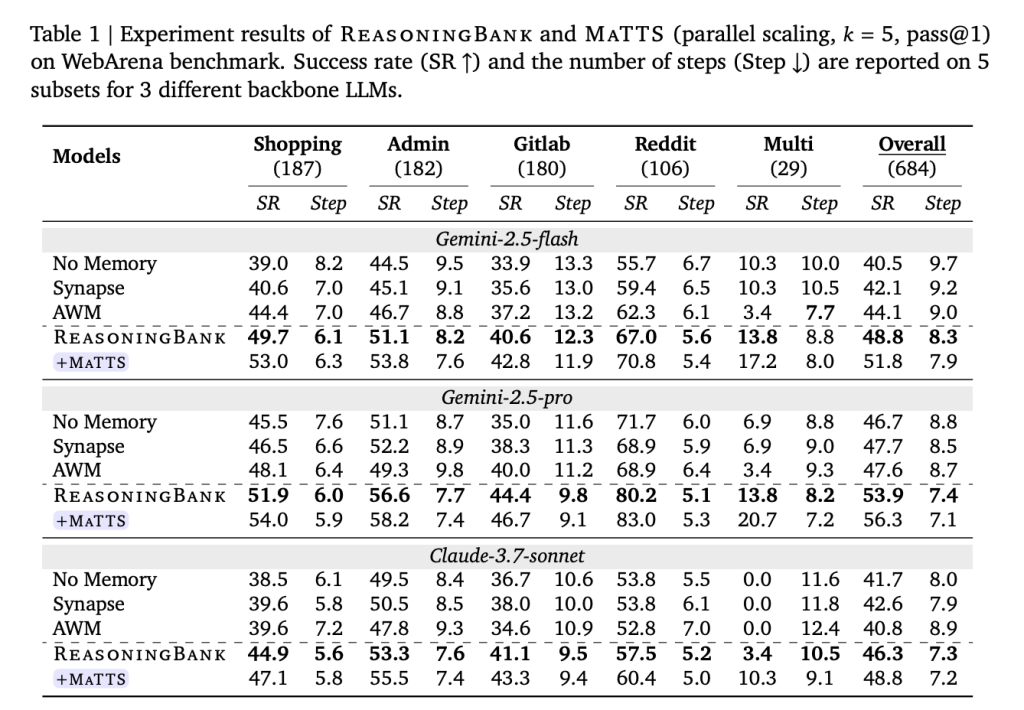
Outcomes Throughout Three Benchmarks
Examined on WebArena (an internet navigation benchmark spanning purchasing, admin, GitLab, and Reddit duties), Mind2Web (which checks generalization throughout cross-task, cross-website, and cross-domain settings), and SWE-Bench-Verified (a repository-level software program engineering benchmark with 500 verified situations), ReasoningBank persistently outperforms all baselines throughout all three datasets and all examined spine fashions.
On WebArena with Gemini-2.5-Flash, ReasoningBank improved total success price by +8.3 share factors over the memory-free baseline (40.5% → 48.8%), whereas lowering common interplay steps by as much as 1.4 in comparison with no-memory and as much as 1.6 in comparison with different reminiscence baselines. The effectivity positive aspects are sharpest on profitable trajectories — on the Purchasing subset, for instance, ReasoningBank reduce 2.1 steps from profitable job completions (a 26.9% relative discount). The agent reaches options quicker as a result of it is aware of the best path, not just because it offers up on failed makes an attempt sooner.
On Mind2Web, ReasoningBank delivers constant positive aspects throughout cross-task, cross-website, and cross-domain analysis splits, with probably the most pronounced enhancements within the cross-domain setting — the place the best diploma of technique switch is required and the place competing strategies like AWM really degrade relative to the no-memory baseline.
On SWE-Bench-Verified, outcomes range meaningfully by spine mannequin. With Gemini-2.5-Professional, ReasoningBank achieves a 57.4% resolve price versus 54.0% for the no-memory baseline, saving 1.3 steps per job. With Gemini-2.5-Flash, the step financial savings are extra dramatic — 2.8 fewer steps per job (30.3 → 27.5) alongside a resolve price enchancment from 34.2% to 38.8%.
Including MaTTS (parallel scaling, ok=5) pushes outcomes additional. ReasoningBank with MaTTS reaches 56.3% total SR on WebArena with Gemini-2.5-Professional — in comparison with 46.7% for the no-memory baseline — whereas additionally lowering common steps from 8.8 to 7.1 per job.
Emergent Technique Evolution
Some of the putting findings is that ReasoningBank’s reminiscence doesn’t keep static — it evolves. In a documented case examine, the agent’s preliminary reminiscence gadgets for a “Person-Particular Info Navigation” technique resemble easy procedural checklists: “actively search for and click on on ‘Subsequent Web page,’ ‘Web page X,’ or ‘Load Extra’ hyperlinks.” Because the agent accumulates expertise, those self same reminiscence gadgets mature into adaptive self-reflections, then into systematic pre-task checks, and finally into compositional methods like “recurrently cross-reference the present view with the duty necessities; if present information doesn’t align with expectations, reassess out there choices similar to search filters and different sections.” The analysis crew describe this as emergent conduct resembling the educational dynamics of reinforcement studying — taking place fully at check time, with none mannequin weight updates.
Key Takeaways
- Failure is lastly a studying sign: Not like current agent reminiscence techniques (Synapse, AWM) that solely study from profitable trajectories, ReasoningBank distills generalizable reasoning methods from each successes and failures — turning errors into preventative guardrails for future duties.
- Reminiscence gadgets are structured, not uncooked: ReasoningBank doesn’t retailer messy motion logs. It compresses expertise into clear three-part reminiscence gadgets (title, description, content material) which are human-interpretable and immediately injectable into an agent’s system immediate by way of embedding-based similarity search.
- High quality beats amount in retrieval: The optimum retrieval is ok=1, only one reminiscence merchandise per job. Retrieving extra recollections progressively hurts efficiency (49.7% SR at ok=1 drops to 44.4% at ok=4), making relevance of retrieved reminiscence extra vital than quantity.
- Reminiscence and test-time scaling create a virtuous cycle. MaTTS (memory-aware test-time scaling) makes use of numerous exploration trajectories as contrastive indicators to forge stronger recollections, which in flip information higher exploration — a suggestions loop that pushes WebArena success charges to 56.3% with Gemini-2.5-Professional, up from 46.7% with no reminiscence.
Take a look at the Paper, Repo and Technical particulars. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 130k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you possibly can be part of us on telegram as properly.
Have to companion with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and so forth.? Join with us

{kind=link}