
[ad_1]
By Petros Koutoupis, VDURA
With all the excitement round synthetic intelligence and machine studying, it’s straightforward to lose sight of which high-performance computing storage necessities are important to ship actual, transformative worth in your group.
When evaluating a knowledge storage resolution, one of the widespread efficiency metrics is enter/output operations per second (IOPS). It has lengthy been the usual for measuring storage efficiency, and relying on the workload, a system’s IOPS might be crucial.
In follow, when a vendor advertises IOPS, they’re actually showcasing what number of discontiguous 4 KiB reads or writes the system can deal with below the worst-case situation of absolutely random I/O. Measuring storage efficiency by IOPS is just significant if the workloads are IOPS-intensive (e.g., databases, virtualized environments, or net servers). However as we transfer into the period of AI, the query stays: does IOPS nonetheless matter?
A Breakdown of your Normal AI Workload
AI workloads run throughout your complete information lifecycle, and every stage places its personal spin on GPU compute (with CPUs supporting orchestration and preprocessing), storage, and information administration sources. Listed here are among the commonest varieties you’ll come throughout when constructing and rolling out AI options.
AI workflows (supply: VDURA)
Knowledge Ingestion & Preprocessing
Throughout this stage, uncooked information is collected from sources corresponding to databases, social media platforms, IoT gadgets, and APIs (as examples), then fed into AI pipelines to arrange it for evaluation. Earlier than that evaluation can occur, nonetheless, the information should be cleaned, eradicating inconsistencies, corrupt or irrelevant entries, filling in lacking values, and aligning codecs (such
as timestamps or items of measurement), amongst different duties.
Mannequin Coaching
After the information is prepped, it’s time for probably the most demanding section: coaching. Right here, massive language fashions (LLMs) are constructed by processing information to identify patterns and relationships that drive correct predictions. This stage leans closely on high-performance GPUs, with frequent checkpoints to storage so coaching can shortly recuperate from {hardware} or job failures. In lots of instances, some extent of fine-tuning or comparable changes can also be a part of the method.
Positive-Tuning
Mannequin coaching usually entails constructing a basis mannequin from scratch on massive datasets to seize broad, basic information. Positive-tuning then refines this pre-trained mannequin for a selected activity or area utilizing smaller, specialised datasets, enhancing its efficiency.
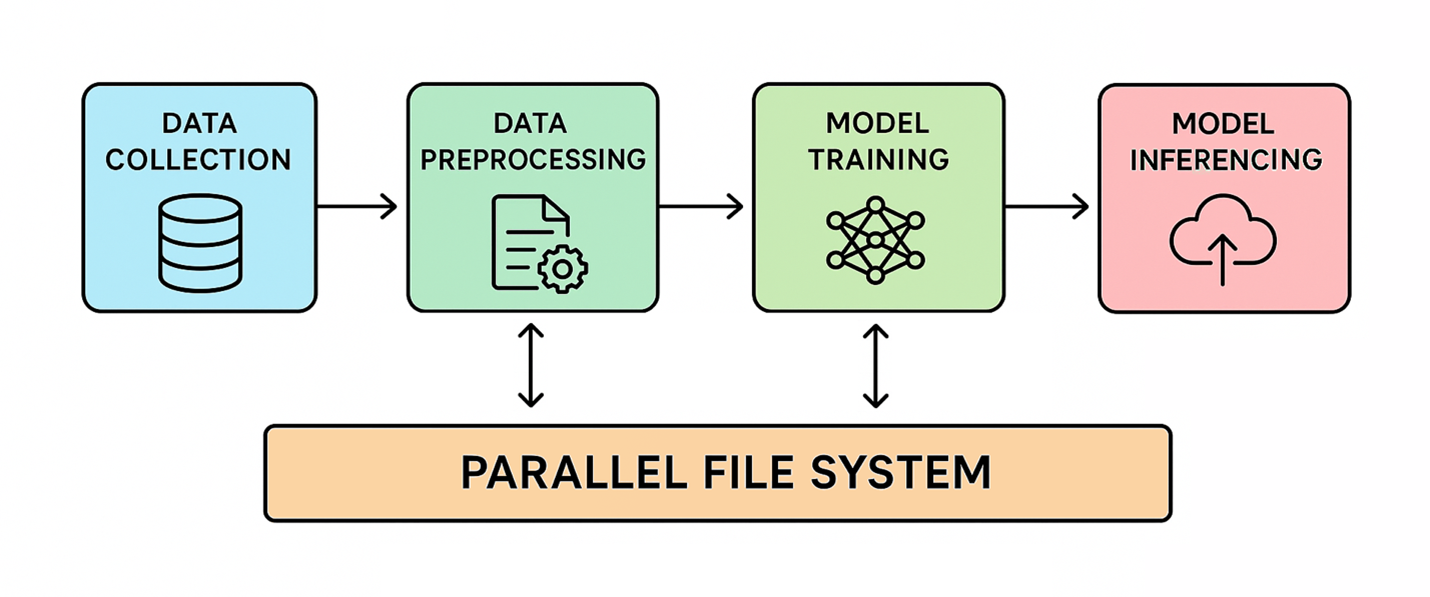
AI workflows (supply: VDURA)
Mannequin Inference
As soon as educated, the AI mannequin could make predictions on new, relatively than historic, information by making use of the patterns it has discovered to generate actionable outputs. For instance, in the event you present the mannequin an image of a canine it has by no means seen earlier than, it should predict: “That could be a canine.”
How Excessive-Efficiency File Storage is Affected
An HPC parallel file system breaks information into chunks and distributes them throughout a number of networked storage servers. This enables many compute nodes to entry the information concurrently at excessive speeds. Because of this, this structure has turn into important for data-intensive workloads, together with AI.
Through the information ingestion section, uncooked information comes from many sources, and parallel file methods might play a restricted position. Their significance will increase throughout preprocessing and mannequin coaching, the place high-throughput methods are wanted to shortly load and rework massive datasets. This reduces the time required to arrange datasets for each coaching and inference.
Checkpointing throughout mannequin coaching periodically saves the present state of the mannequin to guard in opposition to progress loss on account of interruptions. This course of requires all nodes to save lots of the mannequin’s state concurrently, demanding excessive peak storage throughput to maintain checkpointing time minimal. Inadequate storage efficiency throughout checkpointing can lengthen coaching occasions and improve the chance of knowledge loss.
It’s evident that AI workloads are pushed by throughput, not IOPS. Coaching massive fashions requires streaming huge sequential datasets, typically gigabytes to terabytes in measurement, into GPUs. The actual bottleneck is mixture bandwidth (GB/s or TB/s), relatively than dealing with hundreds of thousands of small, random I/O operations per second. Inefficient storage can create bottlenecks, leaving GPUs and different processors idle, slowing coaching, and driving up prices.
Necessities based mostly solely on IOPS can considerably inflate the storage price range or rule out probably the most appropriate architectures. Parallel file methods, however, excel in throughput and scalability. To satisfy particular IOPS targets, manufacturing file methods are sometimes over-engineered, including value or pointless capabilities, relatively than being designed for optimum throughput.
Conclusion
AI workloads demand high-throughput storage relatively than excessive IOPS. Whereas IOPS has lengthy been a regular metric, fashionable AI — notably throughout information preprocessing, mannequin coaching, and checkpointing — depends on shifting huge sequential datasets effectively to maintain GPUs and compute nodes absolutely utilized. Parallel file methods present the required scalability and bandwidth to deal with these workloads successfully, whereas focusing solely on IOPS can result in over-engineered, expensive options that don’t optimize coaching efficiency. For AI at scale, throughput and mixture bandwidth are the true drivers of productiveness and value effectivity.
Writer: Petros Koutoupis has spent greater than 20 years within the information storage business, working for firms which embody Xyratex, Cleversafe/IBM, Seagate, Cray/HPE and, now, AI and HPC information platform firm VDURA.
[ad_2]


")

{kind=link}